JAVA
一. 类的加载过程,Person person = new Person();为例进行说明。
1).因为new用到了Person.class,所以会先找到Person.class文件,并加载到内存中;
2).执行该类中的static代码块,如果有的话,给Person.class类进行初始化;
3).在堆内存中开辟空间分配内存地址;
4).在堆内存中建立对象的特有属性,并进行默认初始化;
5).对属性进行显示初始化;
6).对对象进行构造代码块初始化;
7).对对象进行与之对应的构造函数进行初始化;
8).将内存地址付给栈内存中的p变量
二. JVM相关知识,GC机制。
JVM基本构成

从上图可知,JVM主要包括四个部分:
1.类加载器(ClassLoader):在JVM启动时或者在类运行时将需要的class加载到JVM中。(下图表示了从java源文件到JVM的整个过程,可配合理解。

2.执行引擎:负责执行class文件中包含的字节码指令;
3.内存区(也叫运行时数据区):是在JVM运行的时候操作所分配的内存区。运行时内存区主要可以划分为5个区域,如图:

-
方法区(Method Area):用于存储类结构信息的地方,包括常量池、静态变量、构造函数等。虽然JVM规范把方法区描述为堆的一个逻辑部分, 但它却有个别名non-heap(非堆),所以大家不要搞混淆了。方法区还包含一个运行时常量池。
-
java堆(Heap):存储java实例或者对象的地方。这块是GC的主要区域。从存储的内容我们可以很容易知道,方法区和堆是被所有java线程共享的。
-
java栈(Stack):java栈总是和线程关联在一起,每当创建一个线程时,JVM就会为这个线程创建一个对应的java栈。在这个java栈中又会包含多个栈帧,每运行一个方法就创建一个栈帧,用于存储局部变量表、操作栈、方法返回值等。每一个方法从调用直至执行完成的过程,就对应一个栈帧在java栈中入栈到出栈的过程。所以java栈是现成私有的。
-
程序计数器(PC Register):用于保存当前线程执行的内存地址。由于JVM程序是多线程执行的(线程轮流切换),所以为了保证线程切换回来后,还能恢复到原先状态,就需要一个独立的计数器,记录之前中断的地方,可见程序计数器也是线程私有的。
-
本地方法栈(Native Method Stack):和java栈的作用差不多,只不过是为JVM使用到的native方法服务的。
4.本地方法接口:主要是调用C或C++实现的本地方法及返回结果。
GC机制
垃圾收集器一般必须完成两件事:检测出垃圾;回收垃圾。怎么检测出垃圾?一般有以下几种方法:
引用计数法:
给一个对象添加引用计数器,每当有个地方引用它,计数器就加1;引用失效就减1。好了,问题来了,如果我有两个对象A和B,互相引用,除此之外,没有其他任何对象引用它们,实际上这两个对象已经无法访问,即是我们说的垃圾对象。但是互相引用,计数不为0,导致无法回收,所以还有另一种方法:
可达性分析算法:
以根集对象为起始点进行搜索,如果有对象不可达的话,即是垃圾对象。这里的根集一般包括java栈中引用的对象、方法区常良池中引用的对象、本地方法中引用的对象等。
总之,JVM在做垃圾回收的时候,会检查堆中的所有对象是否会被这些根集对象引用,不能够被引用的对象就会被垃圾收集器回收。一般回收算法也有如下几种:
1).标记-清除(Mark-sweep)
2).复制(Copying
3).标记-整理(Mark-Compact)
4).分代收集算法
具体的解释可以参考本篇文章还不点我?
三. 类的加载器,双亲机制,Android的类加载器。
类的加载器
大家都知道,当我们写好一个Java程序之后,不是管是CS还是BS应用,都是由若干个.class文件组织而成的一个完整的Java应用程序,当程序在运行时,即会调用该程序的一个入口函数来调用系统的相关功能,而这些功能都被封装在不同的class文件当中,所以经常要从这个class文件中要调用另外一个class文件中的方法,如果另外一个文件不存在的,则会引发系统异常。而程序在启动的时候,并不会一次性加载程序所要用的所有class文件,而是根据程序的需要,通过Java的类加载机制(ClassLoader)来动态加载某个class文件到内存当中的,从而只有class文件被载入到了内存之后,才能被其它class所引用。所以ClassLoader就是用来动态加载class文件到内存当中用的。
双亲机制
1、原理介绍
ClassLoader使用的是双亲委托模型来搜索类的,每个ClassLoader实例都有一个父类加载器的引用(不是继承的关系,是一个包含的关系),虚拟机内置的类加载器(Bootstrap ClassLoader)本身没有父类加载器,但可以用作其它ClassLoader实例的的父类加载器。当一个ClassLoader实例需要加载某个类时,它会试图亲自搜索某个类之前,先把这个任务委托给它的父类加载器,这个过程是由上至下依次检查的,首先由最顶层的类加载器Bootstrap ClassLoader试图加载,如果没加载到,则把任务转交给Extension ClassLoader试图加载,如果也没加载到,则转交给App ClassLoader 进行加载,如果它也没有加载得到的话,则返回给委托的发起者,由它到指定的文件系统或网络等URL中加载该类。如果它们都没有加载到这个类时,则抛出ClassNotFoundException异常。否则将这个找到的类生成一个类的定义,并将它加载到内存当中,最后返回这个类在内存中的Class实例对象。
2、为什么要使用双亲委托这种模型呢?
因为这样可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子ClassLoader再加载一次。考虑到安全因素,我们试想一下,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义的类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时就被引导类加载器(Bootstrcp ClassLoader)加载,所以用户自定义的ClassLoader永远也无法加载一个自己写的String,除非你改变JDK中ClassLoader搜索类的默认算法。
3、但是JVM在搜索类的时候,又是如何判定两个class是相同的呢?
JVM在判定两个class是否相同时,不仅要判断两个类名是否相同,而且要判断是否由同一个类加载器实例加载的。只有两者同时满足的情况下,JVM才认为这两个class是相同的。就算两个class是同一份class字节码,如果被两个不同的ClassLoader实例所加载,JVM也会认为它们是两个不同class。比如网络上的一个Java类org.classloader.simple.NetClassLoaderSimple,javac编译之后生成字节码文件NetClassLoaderSimple.class,ClassLoaderA和ClassLoaderB这两个类加载器并读取了NetClassLoaderSimple.class文件,并分别定义出了java.lang.Class实例来表示这个类,对于JVM来说,它们是两个不同的实例对象,但它们确实是同一份字节码文件,如果试图将这个Class实例生成具体的对象进行转换时,就会抛运行时异常java.lang.ClassCaseException,提示这是两个不同的类型。
Android类加载器
对于Android而言,最终的apk文件包含的是dex类型的文件,dex文件是将class文件重新打包,打包的规则又不是简单地压缩,而是完全对class文件内部的各种函数表,变量表进行优化,产生一个新的文件,即dex文件。因此加载这种特殊的Class文件就需要特殊的类加载器DexClassLoader。
四. 集合框架,list,map,set都有哪些具体的实现类,区别都是什么?

1、特点:存储对象;长度可变;存储对象的类型可不同;
2、集合框架:
2)Collection
(1)List:有序的;元素可重复,有索引
(add(index, element)、add(index, Collection)、remove(index)、set(index,element)、get(index)、subList(from, to)、listIterator())
①ArrayList:底层是数组结构,查询快,增删慢,不同步。
②LinkedList:底层是链表结构,增删快,查询慢,不同步
addFist();addLast() getFirst();getLast()
removeFirst();removeLast() 获取并删除元素,无元素将抛异常:NoSuchElementException
替代的方法(JDK1.6):
offerFirst();offerLast();
peekFirst();peekLast();无元素返回null
pollFirst();pollLast();删除并返回此元素,无元素返回null
③Vector:底层是数组结构,线程同步,被ArrayList取代了
注:了对于判断是否存在,以及删除等操作,以依赖的方法是元素的hashCode和equals方法
ArrayList判断是否存在和删除操作依赖的是equals方法
(2)Set:无序的,无索引,元素不可重复
①HashSet:底层是哈希表,线程不同步,无序、高效
保证元素唯一性:通过元素的hashCode和equals方法。若hashCode值相同,则会判断equals的结果是否为true;hashCode不同,不会调用equals方法
LinkedHashSet:有序,是HashSet的子类
②TreeSet:底层是二叉树,可对元素进行排序,默认是自然顺序
保证唯一性:Comparable接口的compareTo方法的返回值
===》TreeSet两种排序方式:两种方式都存在时,以比较器为主
第一种:自然排序(默认排序):
添加的对象需要实现Comparable接口,覆盖compareTo方法
第二种:比较器
添加的元素自身不具备比较性或不是想要的比较方式。将比较器作为参数传递进去。
定义一个类,实现Comparator接口,覆盖compare方法。当主要条件相同时,比较次要条件。
3)Map 集合:
(1)HashTable:底层数据结构是哈希表,不可存入null键和null值。同步的
Properties继承自HashTable,可保存在流中或从流中加载,是集合和IO流的结合产物
(2)HashMap:底层数据结构是哈希表;允许使用null键和null值,不同步,效率高
TreeMap:
底层数据结构时二叉树,不同步,可排序
与Set很像,Set底层就是使用了Map集合
方法:
V put(K key, V value) ; void putAll(Map m)
void clear(); V remove(Object key)
boolean containsKey(Object key); containsValue(Object key); isEmpty()
V get(Object key); int size(); Collection
Set
2.3、Map集合两种取出方式:
第一种:Set
取出Map集合中的所有键放于Set集合中,然后再通过键取出对应的值
Set
Iterator
while(it.hasNext()){
String key = it.next();
String value = map.get(key);
//…..
}
第二种:Set<Map.Entry<K,V» entrySet()
取出Map集合中键值对的映射放于Set集合中,然后通过Map集合中的内部接口,然后通过其中的方法取出
Set<Map.Entry<String,String» entrySet = map.entrySet();
Iterator<Map.Entry<String,String» it = entrySet.iterator();
While(it.hasNext()){
Map.Entry<String,String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
//……
}
2.4、Collection和Map的区别:
Collection:单列集合,一次存一个元素
Map:双列集合,一次存一对集合,两个元素(对象)存在着映射关系
2.5、集合工具类:
Collections:操作集合(一般是list集合)的工具类。方法全为静态的
sort(List list);对list集合进行排序; sort(List list, Comparator c) 按指定比较器排序
fill(List list, T obj);将集合元素替换为指定对象;
swap(List list, int I, int j)交换集合指定位置的元素
shuffle(List list); 随机对集合元素排序
reverseOrder() :返回比较器,强行逆转实现Comparable接口的对象自然顺序
reverseOrder(Comparator c):返回比较器,强行逆转指定比较器的顺序
2.6、Collection和Collections的区别:
Collections:java.util下的工具类,实现对集合的查找、排序、替换、线程安全化等操作。
Collection:是java.util下的接口,是各种单列集合的父接口,实现此接口的有List和Set集合,存储对象并对其进行操作。
3、Arrays:
用于操作数组对象的工具类,全为静态方法
asList():将数组转为list集合
好处:可通过list集合的方法操作数组中的元素:
isEmpty()、contains()、indexOf()、set()
弊端:数组长度固定,不可使用集合的增删操作。
如果数组中存储的是基本数据类型,asList会将数组整体作为一个元素存入集合
集合转为数组:Collection.toArray();
好处:限定了对集合中的元素进行增删操作,只需获取元素
1.List,Set都是继承自Collection接口,Map则不是;
2.List特点:元素有放入顺序,元素可重复;
Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法;
另外list支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值)。
3.Set和List对比:
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
4.Map适合储存键值对的数据。
5.线程安全集合类与非线程安全集合类
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
StringBuilder是非线程安全的,StringBuffer是线程安全的。
下面是这些类具体的使用介绍:
ArrayList与LinkedList的区别和适用场景
Arraylist:
优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
缺点:因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
LinkedList:
优点:LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景。
缺点:因为LinkedList要移动指针,所以查询操作性能比较低。
适用场景分析:
当需要对数据进行对此访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
ArrayList与Vector的区别和适用场景
ArrayList有三个构造方法:
public ArrayList(int initialCapacity)//构造一个具有指定初始容量的空列表。
public ArrayList()//构造一个初始容量为10的空列表。
public ArrayList(Collection<? extends E> c)//构造一个包含指定 collection 的元素的列表
Vector有四个构造方法:
public Vector()//使用指定的初始容量和等于零的容量增量构造一个空向量。
public Vector(int initialCapacity)//构造一个空向量,使其内部数据数组的大小,其标准容量增量为零。
public Vector(Collection<? extends E> c)//构造一个包含指定 collection 中的元素的向量
public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量构造一个空的向量
ArrayList和Vector都是用数组实现的,主要有这么三个区别:
1).Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
2).两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。
3).Vector可以设置增长因子,而ArrayList不可以。
4).Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
适用场景:
1.Vector是线程同步的,所以它也是线程安全的,而ArrayList是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用ArrayList效率比较高。
2.如果集合中的元素的数目大于目前集合数组的长度时,在集合中使用数据量比较大的数据,用Vector有一定的优势。
HashSet与Treeset的适用场景
1.TreeSet 是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值。
2.HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
3.HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例。
适用场景分析:
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
HashMap与TreeMap、HashTable的区别及适用场景
HashMap 非线程安全
HashMap:基于哈希表(散列表)实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。其中散列表的冲突处理主要分两种,一种是开放定址法,另一种是链表法。HashMap的实现中采用的是链表法。
TreeMap:非线程安全基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。
适用场景分析:
HashMap和HashTable:HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允许空键值,而HashTable不允许。
HashMap:适用于Map中插入、删除和定位元素。
Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
(ps:其实我们工作的过程中对集合的使用是很频繁的,稍加注意并总结积累一下,在面试的时候应该会回答的很轻松)
五. concurrentHashmap原理,原子类。
ConcurrentHashMap作为一种线程安全且高效的哈希表的解决方案,尤其其中的”分段锁”的方案,相比HashTable的全表锁在性能上的提升非常之大.
六. volatile原理
在《Java并发编程:核心理论》一文中,我们已经提到过可见性、有序性及原子性问题,通常情况下我们可以通过Synchronized关键字来解决这些个问题,不过如果对Synchronized原理有了解的话,应该知道Synchronized是一个比较重量级的操作,对系统的性能有比较大的影响,所以,如果有其他解决方案,我们通常都避免使用Synchronized来解决问题。而volatile关键字就是Java中提供的另一种解决可见性和有序性问题的方案。对于原子性,需要强调一点,也是大家容易误解的一点:对volatile变量的单次读/写操作可以保证原子性的,如long和double类型变量,但是并不能保证i++这种操作的原子性,因为本质上i++是读、写两次操作。
参考文章插好眼了等传送
七. 多线程的使用场景
使用多线程就一定效率高吗? 有时候使用多线程并不是为了提高效率,而是使得CPU能够同时处理多个事件。
1).为了不阻塞主线程,启动其他线程来做好事的事情,比如APP中耗时操作都不在UI中做.
2).实现更快的应用程序,即主线程专门监听用户请求,子线程用来处理用户请求,以获得大的吞吐量.感觉这种情况下,多线程的效率未必高。 这种情况下的多线程是为了不必等待, 可以并行处理多条数据。
比如JavaWeb的就是主线程专门监听用户的HTTP请求,然后启动子线程去处理用户的HTTP请求。
3).某种虽然优先级很低的服务,但是却要不定时去做。
比如Jvm的垃圾回收。
4.)某种任务,虽然耗时,但是不耗CPU的操作时,开启多个线程,效率会有显著提高。
比如读取文件,然后处理。 磁盘IO是个很耗费时间,但是不耗CPU计算的工作。 所以可以一个线程读取数据,一个线程处理数据。肯定比一个线程读取数据,然后处理效率高。 因为两个线程的时候充分利用了CPU等待磁盘IO的空闲时间。
八. JAVA常量池
Interger中的128(-128~127)
a.当数值范围为-128~127时:如果两个new出来Integer对象,即使值相同,通过“==”比较结果为false,但两个对象直接赋值,则通过“==”比较结果为“true,这一点与String非常相似。
b.当数值不在-128~127时,无论通过哪种方式,即使两个对象的值相等,通过“==”比较,其结果为false;
c.当一个Integer对象直接与一个int基本数据类型通过“==”比较,其结果与第一点相同;
d.Integer对象的hash值为数值本身;
为什么是-128-127?
在Integer类中有一个静态内部类IntegerCache,在IntegerCache类中有一个Integer数组,用以缓存当数值范围为-128~127时的Integer对象。
九. 简单介绍一下java中的泛型,泛型擦除以及相关的概念。
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。 Java语言引入泛型的好处是安全简单。
在Java SE 1.5之前,没有泛型的情况的下,通过对类型Object的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是一个安全隐患。
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
1、泛型的类型参数只能是类类型(包括自定义类),不能是简单类型。
2、同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
3、泛型的类型参数可以有多个。
4、泛型的参数类型可以使用extends语句,例如
5、泛型的参数类型还可以是通配符类型。例如Class<?> classType = Class.forName(“java.lang.String”);
泛型擦除以及相关的概念
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
类型擦除引起的问题及解决方法
1、先检查,在编译,以及检查编译的对象和引用传递的问题
2、自动类型转换
3、类型擦除与多态的冲突和解决方法
4、泛型类型变量不能是基本数据类型
5、运行时类型查询
6、异常中使用泛型的问题
7、数组(这个不属于类型擦除引起的问题)
9、类型擦除后的冲突
10、泛型在静态方法和静态类中的问题
Android
一. Handler机制
* 首先Looper.prepare()会在当前线程保存一个looper对象,并且会维护一个消息队列messageQueue,而且规定了messageQueue在每个线程中只会存在唯一的一个
-
Looper.loop()方法会使线程进入一个无限循环,不断地从消息队列中获取消息,之后回调msg.target.disPatchMessage方法。
-
我们在实例化handler的过程中,会先得到当前所在线程的looper对象,之后得到与该looper对象相对应的消息队列。(代码见handler的构造方法)
-
当我们发送消息的时候,即handler.sendMessage或者handler.post,会将msg中的target赋值为handler自身,之后加入到消息队列中。
-
在第三步实现实例化handler的过程中,我们一般会重写handlerMessage方法(使用post方法需要实现run方法),而这些方法将会在第二步中的msg.target.disPatchMessage方法中被回调,从而实现了message从一个线程到另外一个线程的传递。
Handler机制? MessageQueue,Looper等
二. View的绘制流程
View的绘制流程:OnMeasure()——>OnLayout()——>OnDraw()
各步骤的主要工作:
OnMeasure():
测量视图大小。从顶层父View到子View递归调用measure方法,measure方法又回调OnMeasure。
OnLayout():
确定View位置,进行页面布局。从顶层父View向子View的递归调用view.layout方法的过程,即父View根据上一步measure子View所得到的布局大小和布局参数,将子View放在合适的位置上。
OnDraw():
绘制视图:ViewRoot创建一个Canvas对象,然后调用OnDraw()。六个步骤:①、绘制视图的背景;②、保存画布的图层(Layer);③、绘制View的内容;④、绘制View子视图,如果没有就不用;⑤、还原图层(Layer);⑥、绘制滚动条。
三. 事件传递机制
1).Android事件分发机制的本质是要解决:点击事件由哪个对象发出,经过哪些对象,最终达到哪个对象并最终得到处理。这里的对象是指Activity、ViewGroup、View.
2).Android中事件分发顺序:Activity(Window) -> ViewGroup -> View.
3).事件分发过程由dispatchTouchEvent() 、onInterceptTouchEvent()和onTouchEvent()三个方法协助完成
设置Button按钮来响应点击事件事件传递情况:(如下图)
布局如下:

最外层:Activiy A,包含两个子View:ViewGroup B、View C
中间层:ViewGroup B,包含一个子View:View C
最内层:View C
假设用户首先触摸到屏幕上View C上的某个点(如图中黄色区域),那么Action_DOWN事件就在该点产生,然后用户移动手指并最后离开屏幕。
按钮点击事件:
DOWN事件被传递给C的onTouchEvent方法,该方法返回true,表示处理这个事件;
因为C正在处理这个事件,那么DOWN事件将不再往上传递给B和A的onTouchEvent();
该事件列的其他事件(Move、Up)也将传递给C的onTouchEvent();

(记住这个图的传递顺序,面试的时候能够画出来,就很详细了)
四. Binder机制
1.了解Binder
在Android系统中,每一个应用程序都运行在独立的进程中,这也保证了当其中一个程序出现异常而不会影响另一个应用程序的正常运转。在许多情况下,我们activity都会与各种系统的service打交道,很显然,我们写的程序中activity与系统service肯定不是同一个进程,但是它们之间是怎样实现通信的呢?所以Binder是android中一种实现进程间通信(IPC)的方式之一。
1).首先,Binder分为Client和Server两个进程。
注意,Client和Server是相对的。谁发消息,谁就是Client,谁接收消息,谁就是Server。
举个例子,两个进程A和B之间使用Binder通信,进程A发消息给进程B,那么这时候A是Binder Client,B是Binder Server;进程B发消息给进程A,那么这时候B是Binder Client,A是Binder Server——其实这么说虽然简单了,但还是不太严谨,我们先这么理解着。
2).其次,我们看下面这个图(摘自田维术的博客),基本说明白了Binder的组成解构:

图中的IPC就是进程间通信的意思。
图中的ServiceManager,负责把Binder Server注册到一个容器中。
有人把ServiceManager比喻成电话局,存储着每个住宅的座机电话,还是很恰当的。张三给李四打电话,拨打电话号码,会先转接到电话局,电话局的接线员查到这个电话号码的地址,因为李四的电话号码之前在电话局注册过,所以就能拨通;没注册,就会提示该号码不存在。
对照着Android Binder机制,对着上面这图,张三就是Binder Client,李四就是Binder Server,电话局就是ServiceManager,电话局的接线员在这个过程中做了很多事情,对应着图中的Binder驱动.
3).接下来我们看Binder通信的过程,还是摘自田维术博客的一张图:

注:图中的SM也就是ServiceManager。
我们看到,Client想要直接调用Server的add方法,是不可以的,因为它们在不同的进程中,这时候就需要Binder来帮忙了。
首先是Server在SM这个容器中注册。
其次,Client想要调用Server的add方法,就需要先获取Server对象, 但是SM不会把真正的Server对象返回给Client,而是把Server的一个代理对象返回给Client,也就是Proxy。
然后,Client调用Proxy的add方法,SM会帮他去调用Server的add方法,并把结果返回给Client。
以上这3步,Binder驱动出了很多力,但我们不需要知道Binder驱动的底层实现,涉及到C++的代码了——把有限的时间去做更有意义的事情。
(ps:以上节选自包建强老师的文章点我点我).
2.为什么android选用Binder来实现进程间通信?
1).可靠性。在移动设备上,通常采用基于Client-Server的通信方式来实现互联网与设备间的内部通信。目前linux支持IPC包括传统的管道,System V IPC,即消息队列/共享内存/信号量,以及socket中只有socket支持Client-Server的通信方式。Android系统为开发者提供了丰富进程间通信的功能接口,媒体播放,传感器,无线传输。这些功能都由不同的server来管理。开发都只关心将自己应用程序的client与server的通信建立起来便可以使用这个服务。毫无疑问,如若在底层架设一套协议来实现Client-Server通信,增加了系统的复杂性。在资源有限的手机 上来实现这种复杂的环境,可靠性难以保证。
2).传输性能。socket主要用于跨网络的进程间通信和本机上进程间的通信,但传输效率低,开销大。消息队列和管道采用存储-转发方式,即数据先从发送方缓存区拷贝到内核开辟的一块缓存区中,然后从内核缓存区拷贝到接收方缓存区,其过程至少有两次拷贝。虽然共享内存无需拷贝,但控制复杂。比较各种IPC方式的数据拷贝次数。共享内存:0次。Binder:1次。Socket/管道/消息队列:2次。
3).安全性。Android是一个开放式的平台,所以确保应用程序安全是很重要的。Android对每一个安装应用都分配了UID/PID,其中进程的UID是可用来鉴别进程身份。传统的只能由用户在数据包里填写UID/PID,这样不可靠,容易被恶意程序利用。而我们要求由内核来添加可靠的UID。
所以,出于可靠性、传输性、安全性。android建立了一套新的进程间通信方式。
五. Android中进程的级别,以及各自的区别。
1、前台进程
用户当前正在做的事情需要这个进程。如果满足下面的条件之一,一个进程就被认为是前台进程:
1).这个进程拥有一个正在与用户交互的Activity(这个Activity的onResume()方法被调用)。
2).这个进程拥有一个绑定到正在与用户交互的activity上的Service。
3).这个进程拥有一个前台运行的Service(service调用了方法startForeground()).
4).这个进程拥有一个正在执行其任何一个生命周期回调方法(onCreate(),onStart(),或onDestroy())的Service。
5).这个进程拥有正在执行其onReceive()方法的BroadcastReceiver。
通常,在任何时间点,只有很少的前台进程存在。它们只有在达到无法调合的矛盾时才会被杀--如内存太小而不能继续运行时。通常,到了这时,设备就达到了一个内存分页调度状态,所以需要杀一些前台进程来保证用户界面的反应.
2、可见进程
一个进程不拥有运行于前台的组件,但是依然能影响用户所见。满足下列条件时,进程即为可见:
这个进程拥有一个不在前台但仍可见的Activity(它的onPause()方法被调用)。当一个前台activity启动一个对话框时,就出了这种情况。
3、服务进程
一个可见进程被认为是极其重要的。并且,除非只有杀掉它才可以保证所有前台进程的运行,否则是不能动它的。
这个进程拥有一个绑定到可见activity的Service。
一个进程不在上述两种之内,但它运行着一个被startService()所启动的service。
尽管一个服务进程不直接影响用户所见,但是它们通常做一些用户关心的事情(比如播放音乐或下载数据),所以系统不到前台进程和可见进程活不下去时不会杀它。
4、后台进程
一个进程拥有一个当前不可见的activity(activity的onStop()方法被调用)。
这样的进程们不会直接影响到用户体验,所以系统可以在任意时刻杀了它们从而为前台、可见、以及服务进程们提供存储空间。通常有很多后台进程在运行。它们被保存在一个LRU(最近最少使用)列表中来确保拥有最近刚被看到的activity的进程最后被杀。如果一个activity正确的实现了它的生命周期方法,并保存了它的当前状态,那么杀死它的进程将不会对用户的可视化体验造成影响。因为当用户返回到这个activity时,这个activity会恢复它所有的可见状态。
5、空进程
一个进程不拥有入何active组件。
保留这类进程的唯一理由是高速缓存,这样可以提高下一次一个组件要运行它时的启动速度。系统经常为了平衡在进程高速缓存和底层的内核高速缓存之间的整体系统资源而杀死它们。
六. 线程池的相关知识。
Android中的线程池都是之间或间接通过配置ThreadPoolExecutor来实现不同特性的线程池.Android中最常见的四类具有不同特性的线程池分别为FixThreadPool、CachedThreadPool、SingleThreadPool、ScheduleThreadExecutor.
1).FixThreadPool
只有核心线程,并且数量固定的,也不会被回收,所有线程都活动时,因为队列没有限制大小,新任务会等待执行.
优点:更快的响应外界请求.
2).SingleThreadPool
只有一个核心线程,确保所有的任务都在同一线程中按顺序完成.因此不需要处理线程同步的问题.
3).CachedThreadPool
只有非核心线程,最大线程数非常大,所有线程都活动时,会为新任务创建新线程,否则会利用空闲线程(60s空闲时间,过了就会被回收,所以线程池中有0个线程的可能)处理任务.
优点:任何任务都会被立即执行(任务队列SynchronousQueue相当于一个空集合);比较适合执行大量的耗时较少的任务.
4).ScheduledThreadPool
核心线程数固定,非核心线程(闲着没活干会被立即回收)数没有限制.
优点:执行定时任务以及有固定周期的重复任务
参考Android开发——Android中常见的4种线程池(保证你能看懂并理解)
七. 内存泄露,怎样查找,怎么产生的内存泄露。
产生的内存泄露
1).资源对象没关闭造成的内存泄漏
2).构造Adapter时,没有使用缓存的convertView
3).Bitmap对象不在使用时调用recycle()释放内存
4).试着使用关于application的context来替代和activity相关的context
5).注册没取消造成的内存泄漏
6).集合中对象没清理造成的内存泄漏
7).单例导致内存泄露
单例模式在Android开发中会经常用到,但是如果使用不当就会导致内存泄露。因为单例的静态特性使得它的生命周期同应用的生命周期一样长,如果一个对象已经没有用处了,但是单例还持有它的引用,那么在整个应用程序的生命周期它都不能正常被回收,从而导致内存泄露。
public class AppSettings {
private static AppSettings sInstance;
private Context mContext;
private AppSettings(Context context) {
this.mContext = context;
}
public static AppSettings getInstance(Context context) {
if (sInstance == null) {
sInstance = new AppSettings(context);
}
return sInstance;
}
}
像上面代码中这样的单例,如果我们在调用getInstance(Context context)方法的时候传入的context参数是Activity、Service等上下文,就会导致内存泄露。
以Activity为例,当我们启动一个Activity,并调用getInstance(Context context)方法去获取AppSettings的单例,传入Activity.this作为context,这样AppSettings类的单例sInstance就持有了Activity的引用,当我们退出Activity时,该Activity就没有用了,但是因为sIntance作为静态单例(在应用程序的整个生命周期中存在)会继续持有这个Activity的引用,导致这个Activity对象无法被回收释放,这就造成了内存泄露。
为了避免这样单例导致内存泄露,我们可以将context参数改为全局的上下文:
private AppSettings(Context context) {
this.mContext = context.getApplicationContext();
}
全局的上下文Application Context就是应用程序的上下文,和单例的生命周期一样长,这样就避免了内存泄漏。
单例模式对应应用程序的生命周期,所以我们在构造单例的时候尽量避免使用Activity的上下文,而是使用Application的上下文。
8) 静态变量导致内存泄露
静态变量存储在方法区,它的生命周期从类加载开始,到整个进程结束。一旦静态变量初始化后,它所持有的引用只有等到进程结束才会释放。
比如下面这样的情况,在Activity中为了避免重复的创建info,将sInfo作为静态变量:
public class MainActivity extends AppCompatActivity {
private static Info sInfo;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
if (sInfo != null) {
sInfo = new Info(this);
}
}
}
class Info {
public Info(Activity activity) {
}
}
Info作为Activity的静态成员,并且持有Activity的引用,但是sInfo作为静态变量,生命周期肯定比Activity长。所以当Activity退出后,sInfo仍然引用了Activity,Activity不能被回收,这就导致了内存泄露。
在Android开发中,静态持有很多时候都有可能因为其使用的生命周期不一致而导致内存泄露,所以我们在新建静态持有的变量的时候需要多考虑一下各个成员之间的引用关系,并且尽量少地使用静态持有的变量,以避免发生内存泄露。当然,我们也可以在适当的时候讲静态量重置为null,使其不再持有引用,这样也可以避免内存泄露。
9) 非静态内部类导致内存泄露
非静态内部类(包括匿名内部类)默认就会持有外部类的引用,当非静态内部类对象的生命周期比外部类对象的生命周期长时,就会导致内存泄露。
非静态内部类导致的内存泄露在Android开发中有一种典型的场景就是使用Handler,很多开发者在使用Handler是这样写的:
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
start();
}
private void start() {
Message msg = Message.obtain();
msg.what = 1;
mHandler.sendMessage(msg);
}
private Handler mHandler = new Handler() {
@Override
public void handleMessage(Message msg) {
if (msg.what == 1) {
// 做相应逻辑
}
}
};
}
也许有人会说,mHandler并未作为静态变量持有Activity引用,生命周期可能不会比Activity长,应该不一定会导致内存泄露呢,显然不是这样的!
熟悉Handler消息机制的都知道,mHandler会作为成员变量保存在发送的消息msg中,即msg持有mHandler的引用,而mHandler是Activity的非静态内部类实例,即mHandler持有Activity的引用,那么我们就可以理解为msg间接持有Activity的引用。msg被发送后先放到消息队列MessageQueue中,然后等待Looper的轮询处理(MessageQueue和Looper都是与线程相关联的,MessageQueue是Looper引用的成员变量,而Looper是保存在ThreadLocal中的)。那么当Activity退出后,msg可能仍然存在于消息对列MessageQueue中未处理或者正在处理,那么这样就会导致Activity无法被回收,以致发生Activity的内存泄露。
通常在Android开发中如果要使用内部类,但又要规避内存泄露,一般都会采用_静态内部类+弱引用_的方式。
public class MainActivity extends AppCompatActivity {
private Handler mHandler;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mHandler = new MyHandler(this);
start();
}
private void start() {
Message msg = Message.obtain();
msg.what = 1;
mHandler.sendMessage(msg);
}
private static class MyHandler extends Handler {
private WeakReference<MainActivity> activityWeakReference;
public MyHandler(MainActivity activity) {
activityWeakReference = new WeakReference<>(activity);
}
@Override
public void handleMessage(Message msg) {
MainActivity activity = activityWeakReference.get();
if (activity != null) {
if (msg.what == 1) {
// 做相应逻辑
}
}
}
}
}
mHandler通过弱引用的方式持有Activity,当GC执行垃圾回收时,遇到Activity就会回收并释放所占据的内存单元。这样就不会发生内存泄露了。
上面的做法确实避免了Activity导致的内存泄露,发送的msg不再已经没有持有Activity的引用了,但是msg还是有可能存在消息队列MessageQueue中,所以更好的是在Activity销毁时就将mHandler的回调和发送的消息给移除掉。
@Override
protected void onDestroy() {
super.onDestroy();
mHandler.removeCallbacksAndMessages(null);
}
非静态内部类造成内存泄露还有一种情况就是使用Thread或者AsyncTask。
比如在Activity中直接new一个子线程Thread:
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
new Thread(new Runnable() {
@Override
public void run() {
// 模拟相应耗时逻辑
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
或者直接新建AsyncTask异步任务:
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
new AsyncTask<Void, Void, Void>() {
@Override
protected Void doInBackground(Void... params) {
// 模拟相应耗时逻辑
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
}.execute();
}
}
很多初学者都会像上面这样新建线程和异步任务,殊不知这样的写法非常地不友好,这种方式新建的子线程Thread和AsyncTask都是匿名内部类对象,默认就隐式的持有外部Activity的引用,导致Activity内存泄露。要避免内存泄露的话还是需要像上面Handler一样使用_静态内部类+弱应用_的方式(代码就不列了,参考上面Hanlder的正确写法)。
10) 未取消注册或回调导致内存泄露
比如我们在Activity中注册广播,如果在Activity销毁后不取消注册,那么这个刚播会一直存在系统中,同上面所说的非静态内部类一样持有Activity引用,导致内存泄露。因此注册广播后在Activity销毁后一定要取消注册。
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
this.registerReceiver(mReceiver, new IntentFilter());
}
private BroadcastReceiver mReceiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
// 接收到广播需要做的逻辑
}
};
@Override
protected void onDestroy() {
super.onDestroy();
this.unregisterReceiver(mReceiver);
}
}
在注册观察则模式的时候,如果不及时取消也会造成内存泄露。比如使用Retrofit+RxJava注册网络请求的观察者回调,同样作为匿名内部类持有外部引用,所以需要记得在不用或者销毁的时候取消注册。
11) Timer和TimerTask导致内存泄露
Timer和TimerTask在Android中通常会被用来做一些计时或循环任务,比如实现无限轮播的ViewPager:
public class MainActivity extends AppCompatActivity {
private ViewPager mViewPager;
private PagerAdapter mAdapter;
private Timer mTimer;
private TimerTask mTimerTask;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
init();
mTimer.schedule(mTimerTask, 3000, 3000);
}
private void init() {
mViewPager = (ViewPager) findViewById(R.id.view_pager);
mAdapter = new ViewPagerAdapter();
mViewPager.setAdapter(mAdapter);
mTimer = new Timer();
mTimerTask = new TimerTask() {
@Override
public void run() {
MainActivity.this.runOnUiThread(new Runnable() {
@Override
public void run() {
loopViewpager();
}
});
}
};
}
private void loopViewpager() {
if (mAdapter.getCount() > 0) {
int curPos = mViewPager.getCurrentItem();
curPos = (++curPos) % mAdapter.getCount();
mViewPager.setCurrentItem(curPos);
}
}
private void stopLoopViewPager() {
if (mTimer != null) {
mTimer.cancel();
mTimer.purge();
mTimer = null;
}
if (mTimerTask != null) {
mTimerTask.cancel();
mTimerTask = null;
}
}
@Override
protected void onDestroy() {
super.onDestroy();
stopLoopViewPager();
}
}
当我们Activity销毁的时,有可能Timer还在继续等待执行TimerTask,它持有Activity的引用不能被回收,因此当我们Activity销毁的时候要立即cancel掉Timer和TimerTask,以避免发生内存泄漏。
12) 集合中的对象未清理造成内存泄露
这个比较好理解,如果一个对象放入到ArrayList、HashMap等集合中,这个集合就会持有该对象的引用。当我们不再需要这个对象时,也并没有将它从集合中移除,这样只要集合还在使用(而此对象已经无用了),这个对象就造成了内存泄露。并且如果集合被静态引用的话,集合里面那些没有用的对象更会造成内存泄露了。所以在使用集合时要及时将不用的对象从集合remove,或者clear集合,以避免内存泄漏。
13)资源未关闭或释放导致内存泄露
在使用IO、File流或者Sqlite、Cursor等资源时要及时关闭。这些资源在进行读写操作时通常都使用了缓冲,如果及时不关闭,这些缓冲对象就会一直被占用而得不到释放,以致发生内存泄露。因此我们在不需要使用它们的时候就及时关闭,以便缓冲能及时得到释放,从而避免内存泄露。
14) 属性动画造成内存泄露
动画同样是一个耗时任务,比如在Activity中启动了属性动画(ObjectAnimator),但是在销毁的时候,没有调用cancle方法,虽然我们看不到动画了,但是这个动画依然会不断地播放下去,动画引用所在的控件,所在的控件引用Activity,这就造成Activity无法正常释放。因此同样要在Activity销毁的时候cancel掉属性动画,避免发生内存泄漏。
@Override
protected void onDestroy() {
super.onDestroy();
mAnimator.cancel();
}
15) WebView造成内存泄露
关于WebView的内存泄露,因为WebView在加载网页后会长期占用内存而不能被释放,因此我们在Activity销毁后要调用它的destory()方法来销毁它以释放内存。
另外在查阅WebView内存泄露相关资料时看到这种情况:
Webview下面的Callback持有Activity引用,造成Webview内存无法释放,即使是调用了Webview.destory()等方法都无法解决问题(Android5.1之后)。
最终的解决方案是:在销毁WebView之前需要先将WebView从父容器中移除,然后在销毁WebView。详细分析过程请参考这篇文章: WebView内存泄漏解决方法。
@Override
protected void onDestroy() {
super.onDestroy();
// 先从父控件中移除WebView
mWebViewContainer.removeView(mWebView);
mWebView.stopLoading();
mWebView.getSettings().setJavaScriptEnabled(false);
mWebView.clearHistory();
mWebView.removeAllViews();
mWebView.destroy();
}
总结
内存泄露在Android内存优化是一个比较重要的一个方面,很多时候程序中发生了内存泄露我们不一定就能注意到,所有在编码的过程要养成良好的习惯。总结下来只要做到以下这几点就能避免大多数情况的内存泄漏:
构造单例的时候尽量别用Activity的引用;
静态引用时注意应用对象的置空或者少用静态引用;
使用静态内部类+软引用代替非静态内部类;
及时取消广播或者观察者注册;
耗时任务、属性动画在Activity销毁时记得cancel;
文件流、Cursor等资源及时关闭;
Activity销毁时WebView的移除和销毁。
查找内存泄漏
查找内存泄漏可以使用Android Stdio 自带的Android Profiler工具,也可以使用Square产品的LeadCanary.
八. Android优化
性能优化
1).节制的使用Service 如果应用程序需要使用Service来执行后台任务的话,只有当任务正在执行的时候才应该让Service运行起来。当启动一个Service时,系统会倾向于将这个Service所依赖的进程进行保留,系统可以在LRUcache当中缓存的进程数量也会减少,导致切换程序的时候耗费更多性能。我们可以使用IntentService,当后台任务执行结束后会自动停止,避免了Service的内存泄漏。
2).当界面不可见时释放内存 当用户打开了另外一个程序,我们的程序界面已经不可见的时候,我们应当将所有和界面相关的资源进行释放。重写Activity的onTrimMemory()方法,然后在这个方法中监听TRIM_MEMORY_UI_HIDDEN这个级别,一旦触发说明用户离开了程序,此时就可以进行资源释放操作了。
3).当内存紧张时释放内存 onTrimMemory()方法还有很多种其他类型的回调,可以在手机内存降低的时候及时通知我们,我们应该根据回调中传入的级别来去决定如何释放应用程序的资源。
4).避免在Bitmap上浪费内存 读取一个Bitmap图片的时候,千万不要去加载不需要的分辨率。可以压缩图片等操作。
5).使用优化过的数据集合 Android提供了一系列优化过后的数据集合工具类,如SparseArray、SparseBooleanArray、LongSparseArray,使用这些API可以让我们的程序更加高效。HashMap工具类会相对比较低效,因为它需要为每一个键值对都提供一个对象入口,而SparseArray就避免掉了基本数据类型转换成对象数据类型的时间。
布局优化
1).重用布局文件
标签可以允许在一个布局当中引入另一个布局,那么比如说我们程序的所有界面都有一个公共的部分,这个时候最好的做法就是将这个公共的部分提取到一个独立的布局中,然后每个界面的布局文件当中来引用这个公共的布局。
Tips:如果我们要在标签中覆写layout属性,必须要将layout_width和layout_height这两个属性也进行覆写,否则覆写效果将不会生效。
标签是作为标签的一种辅助扩展来使用的,它的主要作用是为了防止在引用布局文件时引用文件时产生多余的布局嵌套。布局嵌套越多,解析起来就越耗时,性能就越差。因此编写布局文件时应该让嵌套的层数越少越好。
举例:比如在LinearLayout里边使用一个布局。里边又有一个LinearLayout,那么其实就存在了多余的布局嵌套,使用merge可以解决这个问题。
2).仅在需要时才加载布局
某个布局当中的元素不是一起显示出来的,普通情况下只显示部分常用的元素,而那些不常用的元素只有在用户进行特定操作时才会显示出来。
举例:填信息时不是需要全部填的,有一个添加更多字段的选项,当用户需要添加其他信息的时候,才将另外的元素显示到界面上。用VISIBLE性能表现一般,可以用ViewStub。ViewStub也是View的一种,但是没有大小,没有绘制功能,也不参与布局,资源消耗非常低,可以认为完全不影响性能。
<ViewStub
android:id="@+id/view_stub"
android:layout="@layout/profile_extra"
android:layout_width="match_parent"
android:layout_height="wrap_content"
/>
public void onMoreClick() {
ViewStub viewStub = (ViewStub) findViewById(R.id.view_stub);
if (viewStub != null) {
View inflatedView = viewStub.inflate();
editExtra1 = (EditText) inflatedView.findViewById(R.id.edit_extra1);
editExtra2 = (EditText) inflatedView.findViewById(R.id.edit_extra2);
editExtra3 = (EditText) inflatedView.findViewById(R.id.edit_extra3);
}
}
tips:ViewStub所加载的布局是不可以使用标签的,因此这有可能导致加载出来出来的布局存在着多余的嵌套结构。
高性能编码优化
都是一些微优化,在性能方面看不出有什么显著的提升的。使用合适的算法和数据结构是优化程序性能的最主要手段。
1).避免创建不必要的对象 不必要的对象我们应该避免创建:
如果有需要拼接的字符串,那么可以优先考虑使用StringBuffer或者StringBuilder来进行拼接,而不是加号连接符,因为使用加号连接符会创建多余的对象,拼接的字符串越长,加号连接符的性能越低。
当一个方法的返回值是String的时候,通常需要去判断一下这个String的作用是什么,如果明确知道调用方会将返回的String再进行拼接操作的话,可以考虑返回一个StringBuffer对象来代替,因为这样可以将一个对象的引用进行返回,而返回String的话就是创建了一个短生命周期的临时对象。
尽可能地少创建临时对象,越少的对象意味着越少的GC操作。
2).在没有特殊原因的情况下,尽量使用基本数据类型来代替封装数据类型,int比Integer要更加有效,其它数据类型也是一样。
基本数据类型的数组也要优于对象数据类型的数组。另外两个平行的数组要比一个封装好的对象数组更加高效,举个例子,Foo[]和Bar[]这样的数组,使用起来要比Custom(Foo,Bar)[]这样的一个数组高效的多。
3).静态优于抽象
如果你并不需要访问一个对系那个中的某些字段,只是想调用它的某些方法来去完成一项通用的功能,那么可以将这个方法设置成静态方法,调用速度提升15%-20%,同时也不用为了调用这个方法去专门创建对象了,也不用担心调用这个方法后是否会改变对象的状态(静态方法无法访问非静态字段)。
4).对常量使用static final修饰符
static int intVal = 42;
static String strVal = "Hello, world!";
编译器会为上面的代码生成一个初始方法,称为方法,该方法会在定义类第一次被使用的时候调用。这个方法会将42的值赋值到intVal当中,从字符串常量表中提取一个引用赋值到strVal上。当赋值完成后,我们就可以通过字段搜寻的方式去访问具体的值了。
final进行优化:
static final int intVal = 42;
static final String strVal = "Hello, world!";
这样,定义类就不需要方法了,因为所有的常量都会在dex文件的初始化器当中进行初始化。当我们调用intVal时可以直接指向42的值,而调用strVal会用一种相对轻量级的字符串常量方式,而不是字段搜寻的方式。
这种优化方式只对基本数据类型以及String类型的常量有效,对于其他数据类型的常量是无效的。
5).使用增强型for循环语法
static class Counter {
int mCount;
}
Counter[] mArray = ...
public void zero() {
int sum = 0;
for (int i = 0; i < mArray.length; ++i) {
sum += mArray[i].mCount;
} }
public void one() {
int sum = 0;
Counter[] localArray = mArray;
int len = localArray.length;
for (int i = 0; i < len; ++i) {
sum += localArray[i].mCount;
}
}
public void two() {
int sum = 0;
for (Counter a : mArray) {
sum += a.mCount;
}
}
zero()最慢,每次都要计算mArray的长度,one()相对快得多,two()fangfa在没有JIT(Just In Time Compiler)的设备上是运行最快的,而在有JIT的设备上运行效率和one()方法不相上下,需要注意这种写法需要JDK1.5之后才支持。
Tips:ArrayList手写的循环比增强型for循环更快,其他的集合没有这种情况。因此默认情况下使用增强型for循环,而遍历ArrayList使用传统的循环方式。
6).多使用系统封装好的API
系统提供不了的Api完成不了我们需要的功能才应该自己去写,因为使用系统的Api很多时候比我们自己写的代码要快得多,它们的很多功能都是通过底层的汇编模式执行的。 举个例子,实现数组拷贝的功能,使用循环的方式来对数组中的每一个元素一一进行赋值当然可行,但是直接使用系统中提供的System.arraycopy()方法会让执行效率快9倍以上。
7).避免在内部调用Getters/Setters方法
面向对象中封装的思想是不要把类内部的字段暴露给外部,而是提供特定的方法来允许外部操作相应类的内部字段。但在Android中,字段搜寻比方法调用效率高得多,我们直接访问某个字段可能要比通过getters方法来去访问这个字段快3到7倍。但是编写代码还是要按照面向对象思维的,我们应该在能优化的地方进行优化,比如避免在内部调用getters/setters方法。
九. 插件化相关技术,热修补技术是怎样实现的,和插件化有什么区别
相同点:
都使用ClassLoader来实现的加载的新的功能类,都可以使用PathClassLoader与DexClassLoader
不同点:
热修复因为是为了修复Bug的,所以要将新的同名类替代同名的Bug类,要抢先加载新的类而不是Bug类,所以多做两件事:在原先的app打包的时候,阻止相关类去打上CLASS_ISPREVERIFIED标志,还有在热修复时动态改变BaseDexClassLoader对象间接引用的dexElements,这样才能抢先代替Bug类,完成系统不加载旧的Bug类.
而插件化只是增肌新的功能类或者是资源文件,所以不涉及抢先加载旧的类这样的使命,就避过了阻止相关类去打上CLASS_ISPREVERIFIED标志和还有在热修复时动态改变BaseDexClassLoader对象间接引用的dexElements.
所以插件化比热修复简单,热修复是在插件化的基础上在进行替旧的Bug类
十. 怎样计算一张图片的大小,加载bitmap过程(怎样保证不产生内存溢出),二级缓存,LRUCache算法。
计算一张图片的大小
图片占用内存的计算公式:图片高度 * 图片宽度 * 一个像素占用的内存大小.所以,计算图片占用内存大小的时候,要考虑图片所在的目录跟设备密度,这两个因素其实影响的是图片的高宽,android会对图片进行拉升跟压缩。
加载bitmap过程(怎样保证不产生内存溢出)
由于Android对图片使用内存有限制,若是加载几兆的大图片便内存溢出。Bitmap会将图片的所有像素(即长x宽)加载到内存中,如果图片分辨率过大,会直接导致内存OOM,只有在BitmapFactory加载图片时使用BitmapFactory.Options对相关参数进行配置来减少加载的像素。
BitmapFactory.Options相关参数详解
(1).Options.inPreferredConfig值来降低内存消耗。
比如:默认值ARGB_8888改为RGB_565,节约一半内存。
(2).设置Options.inSampleSize 缩放比例,对大图片进行压缩 。
(3).设置Options.inPurgeable和inInputShareable:让系统能及时回 收内存。
A:inPurgeable:设置为True时,表示系统内存不足时可以被回 收,设置为False时,表示不能被回收。
B:inInputShareable:设置是否深拷贝,与inPurgeable结合使用,inPurgeable为false时,该参数无意义。
(4).使用decodeStream代替其他方法。
decodeResource,setImageResource,setImageBitmap等方法
十一. LRUCache算法是怎样实现的。
内部存在一个LinkedHashMap和maxSize,把最近使用的对象用强引用存储在 LinkedHashMap中,给出来put和get方法,每次put图片时计算缓存中所有图片总大小,跟maxSize进行比较,大于maxSize,就将最久添加的图片移除;反之小于maxSize就添加进来。
之前,我们会使用内存缓存技术实现,也就是软引用或弱引用,在Android 2.3(APILevel 9)开始,垃圾回收器会更倾向于回收持有软引用或弱引用的对象,这让软引用和弱引用变得不再可靠。
算法
一. 算法题
m * n的矩阵,能形成几个正方形(2 * 2能形成1个正方形,2 * 3 2个,3 * 3 6个)
计数的关键是要观察到任意一个倾斜的正方形必然唯一内接于一个非倾斜的正方形,而一个非倾斜的边长为k的非倾斜正方形,一条边上有k-1个内点,每个内点恰好确定一个内接于其中的倾斜正方形,加上非倾斜正方形本身,可知,将边长为k的非倾斜正方形数目乘以k,再按k求和即可得到所有正方形的数目。
设2≤n≤m,k≤n-1,则边长为k的非倾斜有
(n-k)(m-k)个,故所有正方形有
∑(m-k)(n-k)k个
例如m=n=4
正方形有3_3_1+2_2_2+1_1_3=20个
下面是面试过程中遇到的题目
大多数题目都可以在上面找到答案.
电话面试题
1.ArrayList 和 Hashmap 简单说一些,区别,底层的数据结构.
2.Handler 消息机制
3.引起内存泄漏的场景
4.多线程的使用场景?
5.常用的线程池有哪几种?
6.在公司做了什么?团队规模?为什么离职?
面试中实际涉及到的问题
第一轮
1.知道哪些单例模式,写一个线程安全的单例,并分析为什么是线程安全的?
public class Singleton {
// Private constructor prevents instantiation from other classes
private Singleton() { }
/**
* SingletonHolder is loaded on the first execution of Singleton.getInstance()
* or the first access to SingletonHolder.INSTANCE, not before.
*/
private static class SingletonHolder {
public static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
2.Java中的集合有哪些?解释一下HashMap?底部的数据结构?散列表冲突的处理方法,散列表是一个什么样的数据结构?HashMap是采用什么方法处理冲突的?
1、特点:存储对象;长度可变;存储对象的类型可不同;
2、集合框架:
2)Collection
(1)List:有序的;元素可重复,有索引
(add(index, element)、add(index, Collection)、remove(index)、set(index,element)、get(index)、subList(from, to)、listIterator())
①**ArrayList**:底层是数组结构,查询快,增删慢,不同步。
②**LinkedList**:底层是链表结构,增删快,查询慢,不同步
addFist();addLast() getFirst();getLast()
removeFirst();removeLast() 获取并删除元素,无元素将抛异常:NoSuchElementException
替代的方法(JDK1.6):
offerFirst();offerLast();
peekFirst();peekLast();无元素返回null
pollFirst();pollLast();删除并返回此元素,无元素返回null
③Vector:底层是数组结构,线程同步,被ArrayList取代了
注:对于判断是否存在,以及删除等操作,以依赖的方法是元素的hashCode和equals方法
ArrayList判断是否存在和删除操作依赖的是equals方法
(2)Set:无序的,无索引,元素不可重复
①HashSet:底层是哈希表,线程不同步,无序、高效
保证元素唯一性:通过元素的hashCode和equals方法。若hashCode值相同,则会判断equals的结果是否为true;hashCode不同,不会调用equals方法
LinkedHashSet:有序,是HashSet的子类
②TreeSet:底层是二叉树,可对元素进行排序,默认是自然顺序
保证唯一性:Comparable接口的compareTo方法的返回值
TreeSet两种排序方式:两种方式都存在时,以比较器为主
第一种:自然排序(默认排序):
添加的对象需要实现Comparable接口,覆盖compareTo方法
第二种:比较器
添加的元素自身不具备比较性或不是想要的比较方式。将比较器作为参数传递进去。
定义一个类,实现Comparator接口,覆盖compare方法。当主要条件相同时,比较次要条件。
3)Map 集合:
(1)HashTable:底层数据结构是哈希表,不可存入null键和null值。同步的
Properties继承自HashTable,可保存在流中或从流中加载,是集合和IO流的结合产物
(2)HashMap:底层数据结构是哈希表;允许使用null键和null值,不同步,效率高
TreeMap:
底层数据结构时二叉树,不同步,可排序
与Set很像,Set底层就是使用了Map集合
方法:
V put(K key, V value) ; void putAll(Map m)
void clear(); V remove(Object key)
boolean containsKey(Object key); containsValue(Object key); isEmpty()
V get(Object key); int size(); Collection<V> values()
Set<K> keySet(); Set<Map.Entry<K,V>> entrySet()
2.3、Map集合两种取出方式:
第一种:Set
取出Map集合中的所有键放于Set集合中,然后再通过键取出对应的值
Set<String> keySet = map.keySet();
Iterator<String> it = keySet.iterator();
while(it.hasNext()){
String key = it.next();
String value = map.get(key);
//…..
}
第二种:Set<Map.Entry<K,V» entrySet()
取出Map集合中键值对的映射放于Set集合中,然后通过Map集合中的内部接口,然后通过其中的方法取出
Set<Map.Entry<String,String>> entrySet = map.entrySet();
Iterator<Map.Entry<String,String>> it = entrySet.iterator();
While(it.hasNext()){
Map.Entry<String,String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
//……
}
2.4、Collection和Map的区别:
Collection:单列集合,一次存一个元素
Map:双列集合,一次存一对集合,两个元素(对象)存在着映射关系
2.5、集合工具类:
Collections:操作集合(一般是list集合)的工具类。方法全为静态的
sort(List list);对list集合进行排序; sort(List list, Comparator c) 按指定比较器排序
fill(List list, T obj);将集合元素替换为指定对象;
swap(List list, int I, int j)交换集合指定位置的元素
shuffle(List list); 随机对集合元素排序
reverseOrder() :返回比较器,强行逆转实现Comparable接口的对象自然顺序
reverseOrder(Comparator c):返回比较器,强行逆转指定比较器的顺序
2.6、Collection和Collections的区别:
Collections:java.util下的工具类,实现对集合的查找、排序、替换、线程安全化等操作。
Collection:是java.util下的接口,是各种单列集合的父接口,实现此接口的有List和Set集合,存储对象并对其进行操作。
3、Arrays:
用于操作数组对象的工具类,全为静态方法
asList():将数组转为list集合
好处:可通过list集合的方法操作数组中的元素:
isEmpty()、contains()、indexOf()、set()
弊端:数组长度固定,不可使用集合的增删操作。
如果数组中存储的是基本数据类型,asList会将数组整体作为一个元素存入集合
集合转为数组:Collection.toArray();
好处:限定了对集合中的元素进行增删操作,只需获取元素
1.List,Set都是继承自Collection接口,Map则不是;
2.List特点:元素有放入顺序,元素可重复;
Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法;
另外list支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值)。
3.Set和List对比:
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
4.Map适合储存键值对的数据。
5.线程安全集合类与非线程安全集合类
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
StringBuilder是非线程安全的,StringBuffer是线程安全的。
下面是这些类具体的使用介绍:
ArrayList与LinkedList的区别和适用场景
Arraylist:
优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
缺点:因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
LinkedList:
优点:LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景。
缺点:因为LinkedList要移动指针,所以查询操作性能比较低。
适用场景分析:
当需要对数据进行对此访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
ArrayList与Vector的区别和适用场景
ArrayList有三个构造方法:
public ArrayList(int initialCapacity)//构造一个具有指定初始容量的空列表。
public ArrayList()//构造一个初始容量为10的空列表。
public ArrayList(Collection<? extends E> c)//构造一个包含指定 collection 的元素的列表
Vector有四个构造方法:
public Vector()//使用指定的初始容量和等于零的容量增量构造一个空向量。
public Vector(int initialCapacity)//构造一个空向量,使其内部数据数组的大小,其标准容量增量为零。
public Vector(Collection<? extends E> c)//构造一个包含指定 collection 中的元素的向量
public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量构造一个空的向量
ArrayList和Vector都是用数组实现的,主要有这么三个区别:
1).Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
2).两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。
3).Vector可以设置增长因子,而ArrayList不可以。
4).Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
适用场景:
1.Vector是线程同步的,所以它也是线程安全的,而ArrayList是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用ArrayList效率比较高。
2.如果集合中的元素的数目大于目前集合数组的长度时,在集合中使用数据量比较大的数据,用Vector有一定的优势。
HashSet与Treeset的适用场景
1.TreeSet 是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值。
2.HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
3.HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例。
适用场景分析:
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
HashMap与TreeMap、HashTable的区别及适用场景
HashMap 非线程安全
HashMap:基于哈希表(散列表)实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。其中散列表的冲突处理主要分两种,一种是开放定址法,另一种是链表法。HashMap的实现中采用的是链表法。
TreeMap:非线程安全基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。
适用场景分析:
HashMap和HashTable:HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允许空键值,而HashTable不允许。
HashMap:适用于Map中插入、删除和定位元素。
Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
(ps:其实我们工作的过程中对集合的使用是很频繁的,稍加注意并总结积累一下,在面试的时候应该会回答的很轻松)
五. concurrentHashmap原理,原子类。
ConcurrentHashMap作为一种线程安全且高效的哈希表的解决方案,尤其其中的”分段锁”的方案,相比HashTable的全表锁在性能上的提升非常之大.
3.解释一下什么是MVP架构,画出图解,一句话解释MVP和MVC的区别?
为了解决逻辑处理和UI视图的松散耦合,MVC和MVP的架构模式在很多App中使用比较广泛。
那什么是MVP呢?它又和我们常常听到的MVC有什么关系了以及区别呢?
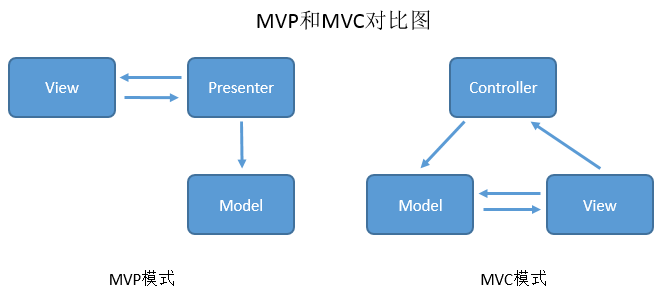
MVP 是从经典的模式MVC演变而来,它们的基本思想有相通的地方:Controller/Presenter负责逻辑的处理,Model提供数据,View负责显示。作为一种新的模式,MVP与MVC有着一个重大的区别:在MVP中View并不直接使用Model,它们之间的通信是通过Presenter (MVC中的Controller)来进行的,所有的交互都发生在Presenter内部,而在MVC中View会从直接Model中读取数据而不是通过 Controller。
在MVC里,View是可以直接访问Model的!从而,View里会包含Model信息,不可避免的还要包括一些业务逻辑。 在MVC模型里,更关注的Model的不变,而同时有多个对Model的不同显示,及View。所以,在MVC模型里,Model不依赖于View,但是View是依赖于Model的。不仅如此,因为有一些业务逻辑在View里实现了,导致要更改View也是比较困难的,至少那些业务逻辑是无法重用的。
MVP如何解决MVC的问题?
在MVP里,Presenter完全把Model和View进行了分离,主要的程序逻辑在Presenter里实现。而且,Presenter与具体的View是没有直接关联的,而是通过定义好的接口进行交互,从而使得在变更View时候可以保持Presenter的不变,即重用! 不仅如此,我们还可以编写测试用的View,模拟用户的各种操作,从而实现对Presenter的测试–而不需要使用自动化的测试工具。 我们甚至可以在Model和View都没有完成时候,就可以通过编写Mock Object(即实现了Model和View的接口,但没有具体的内容的)来测试Presenter的逻辑。 在MVP里,应用程序的逻辑主要在Presenter来实现,其中的View是很薄的一层。因此就有人提出了Presenter First的设计模式,就是根据User Story来首先设计和开发Presenter。在这个过程中,View是很简单的,能够把信息显示清楚就可以了。在后面,根据需要再随便更改View,而对Presenter没有任何的影响了。 如果要实现的UI比较复杂,而且相关的显示逻辑还跟Model有关系,就可以在View和Presenter之间放置一个Adapter。由这个 Adapter来访问Model和View,避免两者之间的关联。而同时,因为Adapter实现了View的接口,从而可以保证与Presenter之间接口的不变。这样就可以保证View和Presenter之间接口的简洁,又不失去UI的灵活性。 在MVP模式里,View只应该有简单的Set/Get的方法,用户输入和设置界面显示的内容,除此就不应该有更多的内容,绝不容许直接访问Model–这就是与MVC很大的不同之处。
MVP的优点:
1、模型与视图完全分离,我们可以修改视图而不影响模型; 2、可以更高效地使用模型,因为所有的交互都发生在一个地方——Presenter内部; 3、我们可以将一个Presenter用于多个视图,而不需要改变Presenter的逻辑。这个特性非常的有用,因为视图的变化总是比模型的变化频繁; 4、如果我们把逻辑放在Presenter中,那么我们就可以脱离用户接口来测试这些逻辑(单元测试)。
使用方法
1、建立bean
public class UserBean {
private String mFirstName;
private String mLastName;
public UserBean(String firstName, String lastName) {
this. mFirstName = firstName;
this. mLastName = lastName;
}
public String getFirstName() {
return mFirstName;
}
public String getLastName() {
return mLastName;
}
}
2、建立model接口(处理业务逻辑,这里指数据读写)
public interface IUserModel {
void setID(int id);
void setFirstName(String firstName);
void setLastName(String lastName);
int getID();
UserBean load(int id);// 通过id读取user信息,返回一个UserBean
}
3、建立view接口(更新ui中的view状态),这里列出需要操作当前view的方法
public interface IUserView {
int getID();
String getFristName();
String getLastName();
void setFirstName(String firstName);
void setLastName(String lastName);
}
4、建立presenter(主导器,通过iView和iModel接口操作model和view),activity可以把所有逻辑给presenter处理,这样java逻辑就从手机的activity中分离出来
public class UserPresenter {
private IUserView mUserView;
private IUserModel mUserModel;
public UserPresenter(IUserView view) {
mUserView = view;
mUserModel = new UserModel();
}
public void saveUser( int id, String firstName, String lastName) {
mUserModel.setID(id);
mUserModel.setFirstName(firstName);
mUserModel.setLastName(lastName);
}
public void loadUser( int id) {
UserBean user = mUserModel.load(id);
mUserView.setFirstName(user.getFirstName()); // 通过调用IUserView的方法来更新显示
mUserView.setLastName(user.getLastName());
}
}
结束语
MVP主要解决就是把逻辑层抽出来成P层,要是遇到需求逻辑上的更改就可以只需要修改P层了或者遇到逻辑上的大概我们可以直接从写一个P也可以,很多开发人员把所有的东西都写在了Activity/Fragment里面这样一来遇到频繁改需求或者逻辑越来越复杂的时候,Activity/Fragment里面就会出现过多的混杂逻辑导致出错,所以MVP模式对于APP来对控制逻辑和UI的解耦来说是一个不错的选择!
在这里多说一下,其实MVP只是一个总体的解决方案。在V和P之间其实我们还可以采用事件总线的方案来解决这种高耦合的情况。本人在另外一篇文章中将会讲到事件总线(otto的bus和eventbus的一个对比分析)
4.Handle消息机制?在使用Handler的时候要注意哪些东西,是否会引起内存泄漏?画一下Handler机制的图解?

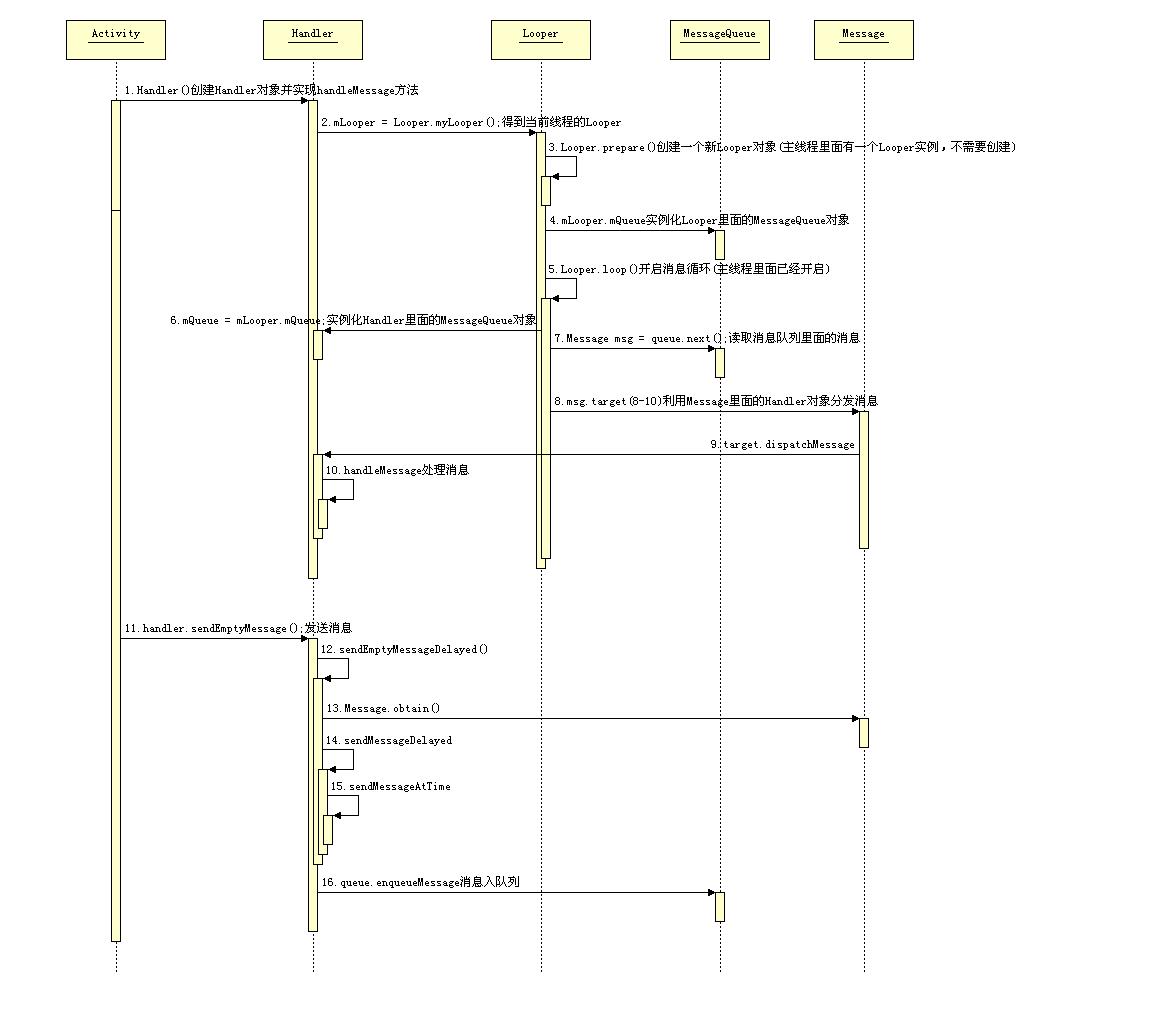
上面一共出现了几种类,ActivityThread,Handler,MessageQueue,Looper,msg(Message),对这些类作简要介绍:
ActivityThread:程序的启动入口,为什么要介绍这个类,是因为该类就是我们说的主线程,它对Looper进行操作的。
Handler:字面意思是操控者,该类有比较重要的地方,就是通过handler来发送消息(sendMessage)到MessageQueue和 操作控件的更新(handleMessage)。handler下面持有这MessageQueue和Looper的对象。
MessageQueue:字面意思是消息队列,就是封装Message类。对Message进行插入和取出操作。
Message:这个类是封装消息体并被发送到MessageQueue中的,给类是通过链表实现的,其好处方便MessageQueue的插入和取出操作。还有一些字段是(int what,Object obj,int arg1,int arg2)。what是用户定义的消息和代码,以便接收者(handler)知道这个是关于什么的。obj是用来传输任意对象的,arg1和arg2是用来传递一些简单的整数类型的。
下面,我们按照启动顺序来进行源码分析:

5.是否做过性能优化?已经采取了哪些措施进行优化?
性能优化
1).节制的使用Service 如果应用程序需要使用Service来执行后台任务的话,只有当任务正在执行的时候才应该让Service运行起来。当启动一个Service时,系统会倾向于将这个Service所依赖的进程进行保留,系统可以在LRUcache当中缓存的进程数量也会减少,导致切换程序的时候耗费更多性能。我们可以使用IntentService,当后台任务执行结束后会自动停止,避免了Service的内存泄漏。
2).当界面不可见时释放内存 当用户打开了另外一个程序,我们的程序界面已经不可见的时候,我们应当将所有和界面相关的资源进行释放。重写Activity的onTrimMemory()方法,然后在这个方法中监听TRIM_MEMORY_UI_HIDDEN这个级别,一旦触发说明用户离开了程序,此时就可以进行资源释放操作了。
3).当内存紧张时释放内存 onTrimMemory()方法还有很多种其他类型的回调,可以在手机内存降低的时候及时通知我们,我们应该根据回调中传入的级别来去决定如何释放应用程序的资源。
4).避免在Bitmap上浪费内存 读取一个Bitmap图片的时候,千万不要去加载不需要的分辨率。可以压缩图片等操作。
5).使用优化过的数据集合 Android提供了一系列优化过后的数据集合工具类,如SparseArray、SparseBooleanArray、LongSparseArray,使用这些API可以让我们的程序更加高效。HashMap工具类会相对比较低效,因为它需要为每一个键值对都提供一个对象入口,而SparseArray就避免掉了基本数据类型转换成对象数据类型的时间。
布局优化
1).重用布局文件
标签可以允许在一个布局当中引入另一个布局,那么比如说我们程序的所有界面都有一个公共的部分,这个时候最好的做法就是将这个公共的部分提取到一个独立的布局中,然后每个界面的布局文件当中来引用这个公共的布局。
Tips:如果我们要在标签中覆写layout属性,必须要将layout_width和layout_height这两个属性也进行覆写,否则覆写效果将不会生效。
标签是作为标签的一种辅助扩展来使用的,它的主要作用是为了防止在引用布局文件时引用文件时产生多余的布局嵌套。布局嵌套越多,解析起来就越耗时,性能就越差。因此编写布局文件时应该让嵌套的层数越少越好。
举例:比如在LinearLayout里边使用一个布局。里边又有一个LinearLayout,那么其实就存在了多余的布局嵌套,使用merge可以解决这个问题。
2).仅在需要时才加载布局
某个布局当中的元素不是一起显示出来的,普通情况下只显示部分常用的元素,而那些不常用的元素只有在用户进行特定操作时才会显示出来。
举例:填信息时不是需要全部填的,有一个添加更多字段的选项,当用户需要添加其他信息的时候,才将另外的元素显示到界面上。用VISIBLE性能表现一般,可以用ViewStub。ViewStub也是View的一种,但是没有大小,没有绘制功能,也不参与布局,资源消耗非常低,可以认为完全不影响性能。
<ViewStub
android:id="@+id/view_stub"
android:layout="@layout/profile_extra"
android:layout_width="match_parent"
android:layout_height="wrap_content"
/>
public void onMoreClick() {
ViewStub viewStub = (ViewStub) findViewById(R.id.view_stub);
if (viewStub != null) {
View inflatedView = viewStub.inflate();
editExtra1 = (EditText) inflatedView.findViewById(R.id.edit_extra1);
editExtra2 = (EditText) inflatedView.findViewById(R.id.edit_extra2);
editExtra3 = (EditText) inflatedView.findViewById(R.id.edit_extra3);
}
}
tips:ViewStub所加载的布局是不可以使用标签的,因此这有可能导致加载出来出来的布局存在着多余的嵌套结构。
高性能编码优化
都是一些微优化,在性能方面看不出有什么显著的提升的。使用合适的算法和数据结构是优化程序性能的最主要手段。
1).避免创建不必要的对象 不必要的对象我们应该避免创建:
如果有需要拼接的字符串,那么可以优先考虑使用StringBuffer或者StringBuilder来进行拼接,而不是加号连接符,因为使用加号连接符会创建多余的对象,拼接的字符串越长,加号连接符的性能越低。
当一个方法的返回值是String的时候,通常需要去判断一下这个String的作用是什么,如果明确知道调用方会将返回的String再进行拼接操作的话,可以考虑返回一个StringBuffer对象来代替,因为这样可以将一个对象的引用进行返回,而返回String的话就是创建了一个短生命周期的临时对象。
尽可能地少创建临时对象,越少的对象意味着越少的GC操作。
2).在没有特殊原因的情况下,尽量使用基本数据类型来代替封装数据类型,int比Integer要更加有效,其它数据类型也是一样。
基本数据类型的数组也要优于对象数据类型的数组。另外两个平行的数组要比一个封装好的对象数组更加高效,举个例子,Foo[]和Bar[]这样的数组,使用起来要比Custom(Foo,Bar)[]这样的一个数组高效的多。
3).静态优于抽象
如果你并不需要访问一个对系那个中的某些字段,只是想调用它的某些方法来去完成一项通用的功能,那么可以将这个方法设置成静态方法,调用速度提升15%-20%,同时也不用为了调用这个方法去专门创建对象了,也不用担心调用这个方法后是否会改变对象的状态(静态方法无法访问非静态字段)。
4).对常量使用static final修饰符
static int intVal = 42;
static String strVal = "Hello, world!";
编译器会为上面的代码生成一个初始方法,称为方法,该方法会在定义类第一次被使用的时候调用。这个方法会将42的值赋值到intVal当中,从字符串常量表中提取一个引用赋值到strVal上。当赋值完成后,我们就可以通过字段搜寻的方式去访问具体的值了。
final进行优化:
static final int intVal = 42;
static final String strVal = "Hello, world!";
这样,定义类就不需要方法了,因为所有的常量都会在dex文件的初始化器当中进行初始化。当我们调用intVal时可以直接指向42的值,而调用strVal会用一种相对轻量级的字符串常量方式,而不是字段搜寻的方式。
这种优化方式只对基本数据类型以及String类型的常量有效,对于其他数据类型的常量是无效的。
5).使用增强型for循环语法
static class Counter {
int mCount;
}
Counter[] mArray = ...
public void zero() {
int sum = 0;
for (int i = 0; i < mArray.length; ++i) {
sum += mArray[i].mCount;
} }
public void one() {
int sum = 0;
Counter[] localArray = mArray;
int len = localArray.length;
for (int i = 0; i < len; ++i) {
sum += localArray[i].mCount;
}
}
public void two() {
int sum = 0;
for (Counter a : mArray) {
sum += a.mCount;
}
}
zero()最慢,每次都要计算mArray的长度,one()相对快得多,two()fangfa在没有JIT(Just In Time Compiler)的设备上是运行最快的,而在有JIT的设备上运行效率和one()方法不相上下,需要注意这种写法需要JDK1.5之后才支持。
Tips:ArrayList手写的循环比增强型for循环更快,其他的集合没有这种情况。因此默认情况下使用增强型for循环,而遍历ArrayList使用传统的循环方式。
6).多使用系统封装好的API
系统提供不了的Api完成不了我们需要的功能才应该自己去写,因为使用系统的Api很多时候比我们自己写的代码要快得多,它们的很多功能都是通过底层的汇编模式执行的。 举个例子,实现数组拷贝的功能,使用循环的方式来对数组中的每一个元素一一进行赋值当然可行,但是直接使用系统中提供的System.arraycopy()方法会让执行效率快9倍以上。
7).避免在内部调用Getters/Setters方法
面向对象中封装的思想是不要把类内部的字段暴露给外部,而是提供特定的方法来允许外部操作相应类的内部字段。但在Android中,字段搜寻比方法调用效率高得多,我们直接访问某个字段可能要比通过getters方法来去访问这个字段快3到7倍。但是编写代码还是要按照面向对象思维的,我们应该在能优化的地方进行优化,比如避免在内部调用getters/setters方法。
6.引起内存泄漏的原因是什么?以及你是怎么解决的?
这些问题应该都是比较基础的问题,每个开发者都应该是非常熟悉并能详细叙述的.这一轮的面试官问的技术都是平时用到的.
产生的内存泄露
1).资源对象没关闭造成的内存泄漏
2).构造Adapter时,没有使用缓存的convertView
3).Bitmap对象不在使用时调用recycle()释放内存
4).试着使用关于application的context来替代和activity相关的context
5).注册没取消造成的内存泄漏
6).集合中对象没清理造成的内存泄漏
Android的虚拟机是基于寄存器的Dalvik,它的最大堆大小一般是16M,有的机器为24M。因此我们所能利用 的内存空间是有限的。如果我们的内存占用超过了一定的水平就会出现OutOfMemory的错误。
内存溢出的几点原因总结: 1、资源释放问题: 程序代码的问题,长期保持某些资源(如Context)的引用,造成内存泄露,资源得不到释放
2、对象内存过大问题: 保存了多个耗用内存过大的对象(如Bitmap),造成内存超出限制
3、static: static是Java中的一个关键字,当用它来修饰成员变量时,那么该变量就属于该类,而不是该类的实例。所以 用static修饰的变量,它的生命周期是很长的,如果用它来引用一些资源耗费过多的实例(Context的情况最多) 这时就要谨慎对待了。
public class ClassName {
private static Context mContext;
//省略 }
以上的代码是很危险的,如果将Activity赋值到mContext的话。那么即使该Activity已经onDestroy,但是由于 仍有对象保存它的引用,因此该Activity依然不会被释放。 我们举Android文档中的一个例子。
private static Drawable sBackground; @Override
protected void onCreate(Bundle state) {
super.onCreate(state);
TextView label = new TextView(this);
label.setText("Leaks are bad");
if (sBackground == null) {
sBackground = getDrawable(R.drawable.large_bitmap); }
label.setBackgroundDrawable(sBackground);
setContentView(label); }
sBackground, 是 一个静态的变量,但是我们发现,我们并没有显式的保存Contex的引用,但是,当Drawable与
View连接之后,Drawable就将View设 置为一个回调,由于View中是包含Context的引用的,所以,实际上我们依
然保存了Context的引用。这个引用链如下: Drawable->TextView->Context
所以,最终该Context也没有得到释放,发生了内存泄露。
针对static的解决方案:
第一、应该尽量避免static成员变量引用资源耗费过多的实例,比如Context。
第二、Context尽量使用Application Context,因为Application的Context的生命周期比较长,引用它不会出现内存 泄露的问题。
第三、使用WeakReference代替强引用。比如可以使用WeakReference
4、线程导致内存溢出: 线程产生内存泄露的主要原因在于线程生命周期的不可控。我们来考虑下面一段代码。
public class MyActivity extends Activity {
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
new MyThread().start();
}
private class MyThread extends Thread{
@Override public void run() {
super.run();
//do somthing }
}
}
这段代码很平常也很简单,是我们经常使用的形式。我们思考一个问题:假设MyThread的run函数是一个很 费时的操作,当我们开启该线程后,将设备的横屏变为了竖屏,一 般情况下当屏幕转换时会重新创建Activity, 按照我们的想法,老的Activity应该会被销毁才对,然而事实上并非如此。
由于我们的线程是Activity的内部类,所以MyThread中保存了Activity的一个引用,当MyThread的run函数没有 结束时,MyThread是不会被销毁的,因此它所引用的老的Activity也不会被销毁,因此就出现了内存泄露的问题。
有些人喜欢用Android提供的AsyncTask,但事实上AsyncTask的问题更加严重,Thread只有在run函数不结束时才出现这种内存泄露问题,然而AsyncTask内部的实现机制是运用了ThreadPoolExcutor,该类产生的Thread对象的生命周期是不确定的,是应用程序无法控制的,因此如果AsyncTask作为Activity的内部类,就更容易出现内存
泄露的问题。
针对这种线程导致的内存泄露问题的解决方案:
第一、将线程的内部类,改为静态内部类。
第二、在线程内部采用弱引用保存Context引用。
二、避免内存溢出的方案: ** 1、图片过大导致内存溢出**: 模拟器的RAM比较小,由于每张图片先前是压缩的情况,放入到Bitmap的时候,大小会变大,导致超出RAM内存
★android 中用bitmap 时很容易内存溢出,报如下错误:Java.lang.OutOfMemoryError : bitmap size exceeds VM budget 解决: 方法1: 主要是加上这段:等比例缩小图片
1)通过getResource()方法获取资源:
//解决加载图片 内存溢出的问题
//Options 只保存图片尺寸大小,不保存图片到内存
BitmapFactory.Options options = new BitmapFactory.Options();
options.inSampleSize = 2;
//缩放的比例,缩放是很难按准备的比例进行缩放的,其值表明缩放的倍数,SDK中建议其值是2的指数值,值越大会导致图片不清晰
BitmapFactory.Options opts = new BitmapFactory.Options();
opts.inSampleSize = 2;
Bitmap bmp = null;
bmp = BitmapFactory.decodeResource(getResources(), mImageIds[position],opts); ...
//回收
bmp.recycle();
2)通过Uri取图片资源 以上代码可以优化内存溢出,但它只是改变图片大小,并不能彻底解决内存溢出。 3)通过路径获取图片资源
方法2:对图片采用软引用,及时地进行recyle()操作
具体见“各种引用的简单了解”中的示例 2、复用listView: 方法:对复杂的listview进行合理设计与编码:
private ImageView preview;
BitmapFactory.Options options = new BitmapFactory.Options();
//图片宽高都为原来的二分之一,即图片为原来的四分之一
options.inSampleSize = 2;
Bitmap bitmap = BitmapFactory.decodeStream(cr.openInputStream(uri), null, options); preview.setImageBitmap(bitmap);
private ImageView preview;
private String fileName= "/sdcard/DCIM/Camera/2010-05-14 16.01.44.jpg"; BitmapFactory.Options options = new BitmapFactory.Options();
//图片宽高都为原来的二分之一,即图片为原来的四分之一
options.inSampleSize = 2;
Bitmap b = BitmapFactory.decodeFile(fileName, options);
preview.setImageBitmap(b); filePath.setText(fileName);
SoftReference<Bitmap> bitmap;
bitmap = new SoftReference<Bitmap>(pBitmap);
if(bitmap != null){
if(bitmap.get() != null && !bitmap.get().isRecycled()){ bitmap.get().recycle();
bitmap= null;
}
}
Adapter中:
@Override
public View getView(int position, View convertView, ViewGroup parent) {
ViewHolder holder;
if(convertView!=null && convertView instanceof LinearLayout){
holder = (ViewHolder) convertView.getTag(); }else{
convertView = View.inflate(MainActivity.this, R.layout.item, null); holder = new ViewHolder();
holder.tv = (TextView)
convertView.findViewById(R.id.tv); convertView.setTag(holder);
}
holder.tv.setText("XXXX");
holder.tv.setTextColor(Color.argb(180, position*4, position*5, 255-position*2)); return convertView;
}
class ViewHolder{
private TextView tv;
}
3、界面切换 方法1:单个页面,横竖屏切换N次后 OOM 1、看看页面布局当中有没有大的图片,比如背景图之类的。
去除xml中相关设置,改在程序中设置背景图(放在onCreate()方法中):
在Activity destory时注意,bg.setCallback(null); 防止Activity得不到及时的释放 2. 跟上面方法相似,直接把xml配置文件加载成view 再放到一个容器里 然后直接调用 this.setContentView(View view);方法,避免xml的重复加载
方法2: 在页面切换时尽可能少地重复使用一些代码 比如:重复调用数据库,反复使用某些对象等等……
4、内存分配: 方法1:Android堆内存也可自己定义大小和优化Dalvik虚拟机的堆内存分配
注意若使用这种方法:project build target 只能选择 <= 2.2 版本,否则编译将通不过。 所以不建议用这种方式
常见的内存使用不当的情况
1、查询数据库没有关闭游标
程序中经常会进行查询数据库的操作,但是经常会有使用完毕Cursor后没有关闭的情况。如果我们的查询结果集比较小,对内存的消耗不容易被发现,只有在常时间大量操作的情况下才会复现内存问题,这样就会给以后的测试和问题排查带来困难和风险。
Drawable bg = getResources().getDrawable(R.drawable.bg); XXX.setBackgroundDrawable(rlAdDetailone_bg); private final static int CWJ_HEAP_SIZE= 610241024; private final static float TARGET_HEAP_UTILIZATION = 0.75f; VMRuntime.getRuntime().setMinimumHeapSize(CWJ_HEAP_SIZE); VMRuntime.getRuntime().setTargetHeapUtilization(TARGET_HEAP_UTILIZATION); Cursor cursor = null; try { cursor = getContentResolver().query(uri …); if (cursor != null && cursor.moveToNext()) { … … } } finally { if (cursor != null) { try { cursor.close(); } catch (Exception e) { //ignore this } } }
2、构造Adapter时,没有使用缓存的 convertView
以构造ListView的BaseAdapter为例,在BaseAdapter中提供了方法: public View getView(int position, View convertView, ViewGroup parent)
来向ListView提供每一个item所需要的view对象。初始时ListView会从BaseAdapter中根据当前的屏幕布局实例 化一定数量的 view对象,同时ListView会将这些view对象缓存起来。当向上滚动ListView时,原先位于最上面的 list item的view对象会被回收,然后被用来构造新出现的最下面的list item。这个构造过程就是由getView()方法完成的,getView()的第二个形参 View convertView就是被缓存起来的list item的view对象(初始化时缓存中没有view对 象则convertView是null)。 由此可以看出,如果我们不去使用convertView,而是每次都在getView()中重新实例化一个View对象的话,即浪费资源也浪费时间,也会使得内存占用越来越大。ListView回收list item的view对象的过程可以查看:
public View getView(int position, View convertView, ViewGroup parent) { View view = null;
if (convertView != null) {
view = convertView;
populate(view, getItem(position)); ...
} else {
view = new Xxx(...);
...
}
return view;
}
3、Bitmap对象不在使用时调用recycle()释放内存 有时我们会手工的操作Bitmap对象,如果一个Bitmap对象比较占内存,当它不在被使用的时候,可以调用 Bitmap.recycle()方法回收此对象的像素所占用的内存,但这不是必须的,视情况而定。
4、释放对象的引用 当一个生命周期较短的对象A,被一个生命周期较长的对象B保有其引用的情况下,在A的生命周期结束时,
要在B中清除掉对A的引用。 示例A:
public class DemoActivity extends Activity { ... ...
private Handler mHandler = ... private Object obj;
public void operation() {
obj = initObj();
...
[Mark]
mHandler.post(new Runnable() {
public void run() { useObj(obj);
}
});
} }
我们有一个成员变量 obj,在operation()中我们希望能够将处理obj实例的操作post到某个线程的MessageQueue 中。在以上的代码中,即便是 mHandler所在的线程使用完了obj所引用的对象,但这个对象仍然不会被垃圾回收掉,因为DemoActivity.obj还保有这个对象的引用。 所以如果在DemoActivity中不再使用这个对象了,可以在 [Mark]的位置释放对象的引用,而代码可以修改为:
... ...
public void operation() {
obj = initObj();
...
final Object o = obj;
obj = null;
mHandler.post(new Runnable() { public void run() {
useObj(o); }
}
}
... ...
示例B: 假设我们希望在锁屏界面(LockScreen)中,监听系统中的电话服务以获取一些信息(如信号强度等),则可以在 LockScreen中定义一个PhoneStateListener的对象,同时将它注册到TelephonyManager服务中。对于LockScreen对象,当需要显示锁屏界 面的时候就会创建一个LockScreen对象,而当锁屏界面消失的时候LockScreen对象就会被释放掉。 但是如果在释放LockScreen对象的时候忘记取消我们之前注册的PhoneStateListener对象,则会导致LockScreen无 法被垃 圾回收。如果不断的使锁屏界面显示和消失,则最终会由于大量的LockScreen对象没有办法被回收而引起OutOfMemory,使得system_process进程挂掉。
5、其他 Android应用程序中最典型的需要注意释放资源的情况是在Activity的生命周期中,在onPause()、onStop()、 onDestroy()方法中需要适当的释放资源的情况。由于此情况很基础,在此不详细说明,具体可以查看官方文档对Activity生命周期的介绍,以明确何时应该释放哪些资源。
第二轮
1.关于并发理解多少?说几个并发的集合?
Java 并发编程:核心理论: 共享性,互斥性,原子性,可见性,有序性
什么是并发: 同时在做几件事就是并发
并发的好处 1.提高资源利用率 当一个任务并没有完全占用系统资源时,可以利用并发来提高资源利用率,从而能更快的完成任务 2.在程序任务上更加精简 任务明确分配好,又能同时进行,既提高了效率,逻辑又清晰 3.更好的响应程序 例如图片的上传,页面正常展示没有卡顿,又能正常上传图片,既保证了页面能正常响应,又保证图片能正常上传
并发的风险 1.并发的代价 需要占用更多资源 设计好一个并发程序并不容易 并发的资源交互问题复杂
2.并发的隐患 滥用资源导致系统不稳定 结果与预期不符 出现的BUG难以排查
Java并发集合框架
我们着重说明一下Java并发的集合框架,就是java.util.concurrent包下的集合类
- 非阻塞队列
非阻塞队列就是在队列中没有数据时,对此队列的操作将出现异常或者返回null,无需等待/阻塞的特色。
在JDK的并发包中,常见的非阻塞队列有以下几个:
- ConcurrentHashMap
- ConcurrentSkipListMap
- ConcurrentSkipListSet
- ConcurrentLinkedQueue
- ConcurrentLinkedDeque
- CopyOnWriteArrayList
- CopyOnWriteArraySet
ConcurrentHashMap类
这个类是支持并发操作的Map对象,与之对应的不支持并发操作的Map对象是HashMap,Hashtable对象也是Map的一个子类,也是支持并发操作,但是其不支持Iterator并发的删除操作,如果程序中要对map集合做并发以及Iterator并发编辑/删除操作,推荐使用ConcurrentHashMap集合类。
HashMap集合不支持并发示例:
package com.collections.hashmapdemo;
import java.util.HashMap;
public class HashMapDemo {
public static HashMap hashMap = new HashMap();
public static void main(String[] args) {
Thread threadA = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
hashMap.put("ThreadA" + (i + 1), "ThreadA" + i + 1);
System.out.println("ThreadA" + (i + 1));
}
}
});
Thread threadB = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
hashMap.put("ThreadB" + (i + 1), "ThreadB" + i + 1);
System.out.println("ThreadB" + (i + 1));
}
}
});
threadA.start();
threadB.start();
}
}
执行结果 有时候程序可以正常执行完,有时候则程序会造成假死的状态,如下图:

所以说HashMap不支持多线程并发的操作。
Hashtable集合支持并发 示例: 只需要把HashMap示例中public static HashMap hashMap = new HashMap();修改成public static Hashtable hashtable = new Hashtable();即可。 我们就说说Hashtable不支持Iterator的编辑/删除操作,示例如下
package com.collections.hashmapdemo;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.concurrent.TimeUnit;
public class HashtableNotModifyDemo {
public static Hashtable hashtable = new Hashtable();
static {
for (int i = 0; i < 5; i++) {
hashtable.put("String" + (i + 1), i + 1);
}
}
public static void main(String[] args) {
Thread threadA = new Thread(new Runnable() {
@Override
public void run() {
try {
Iterator iterator = hashtable.keySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
TimeUnit.SECONDS.sleep(2);
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
Thread threadB = new Thread(new Runnable() {
@Override
public void run() {
hashtable.put("z", "zValue");
}
});
threadA.start();
threadB.start();
}
}
执行结果
String5 java.util.ConcurrentModificationException at java.util.HashtableEnumerator.next(Hashtable.java:1167)atcom.collections.hashmapdemo.HashtableNotModifyDemo1.run(HashtableNotModifyDemo.java:22) at java.lang.Thread.run(Thread.java:745)
说明多线程调用该类的iterator()方法返回Iterator对象后,在调用put方法会报ConcurrentModificationException异常,也就是不支持Iterator并发的编辑/删除操作。如果想实现此功能推荐使用并发集合框架提供的ConcurrentHashMap类。
ConcurrentHashMap集合支持并发示例:
需要把HashMap示例中public static HashMap hashMap = new HashMap();修改成public static ConcurrentHashMap concurretHashMap = new ConcurrentHashMap();即可。
ConcurrentHashMap集合支持Iterator并发操作示例:
把类HashtableNotModifyDemo中的public static Hashtable hashtable = new Hashtable();修改为public static ConcurrentHashMap concurretHashMap = new ConcurrentHashMap();测试即可。
ConcurrentSkipListMap类
这个并发集合类支持排序功能。一般此集合中存放的对象要实现Comparable接口,方便此集合类排序,如果不实现此接口,则会按照默认排序。
ConcurrentSkipListSet类
这个并发集合类不仅支持排序功能,还不允许重复的元素。一般此集合中存放的对象要实现Comparable接口,并且重写equals和hashCode方法。
ConcurrentLinkedQueue类
这个并发集合类提供了并发环境的队列操作。
- poll()当没有获取到数据时返回null,如果有数据则一处表头并将表头数据返回。
- element()当没有获取到数据时抛NoSuchElementException异常,如果有数据则返回表头数据。
- peek()当没有获取导数据是返回null,获取到数据时则不移除表头,并将表头数据返回。
ConcurrentLinkedDeque类
ConcurrentLinkedQueue支持对队列头操作,而ConcurrentLinkedDeque也支持队列头和列尾双向操作。
CopyOnWriteArrayList类
ArrayList是线程不安全的,如果想在并发中实现线程安全,则可以使用CopyOnWriteArrayList类,使用方法和ArrayList无异。
CopyOnWriteArraySet类
ArraySet是线程不安全的,如果想在并发中实现线程安全,则可以使用CopyOnWriteArraySet类,使用方法和ArraySet无异。
2.Handler 消息机制图解?
上面一共出现了几种类,ActivityThread,Handler,MessageQueue,Looper,msg(Message),对这些类作简要介绍:
ActivityThread:程序的启动入口,为什么要介绍这个类,是因为该类就是我们说的主线程,它对Looper进行操作的。
Handler:字面意思是操控者,该类有比较重要的地方,就是通过handler来发送消息(sendMessage)到MessageQueue和 操作控件的更新(handleMessage)。handler下面持有这MessageQueue和Looper的对象。
MessageQueue:字面意思是消息队列,就是封装Message类。对Message进行插入和取出操作。
Message:这个类是封装消息体并被发送到MessageQueue中的,给类是通过链表实现的,其好处方便MessageQueue的插入和取出操作。还有一些字段是(int what,Object obj,int arg1,int arg2)。what是用户定义的消息和代码,以便接收者(handler)知道这个是关于什么的。obj是用来传输任意对象的,arg1和arg2是用来传递一些简单的整数类型的。
下面,我们按照启动顺序来进行源码分析:
3.在项目中做了哪些东西?
负责用户版App社区模块的版本的功能迭代,几个组件的开发与管理。
4.画图说明View 事件传递机制?并举一个例子阐述
1).Android事件分发机制的本质是要解决:点击事件由哪个对象发出,经过哪些对象,最终达到哪个对象并最终得到处理。这里的对象是指Activity、ViewGroup、View.
2).Android中事件分发顺序:Activity(Window) -> ViewGroup -> View.
3).事件分发过程由dispatchTouchEvent() 、onInterceptTouchEvent()和onTouchEvent()三个方法协助完成
设置Button按钮来响应点击事件事件传递情况:(如下图)
布局如下:
最外层:Activiy A,包含两个子View:ViewGroup B、View C
中间层:ViewGroup B,包含一个子View:View C
最内层:View C
假设用户首先触摸到屏幕上View C上的某个点(如图中黄色区域),那么Action_DOWN事件就在该点产生,然后用户移动手指并最后离开屏幕。
按钮点击事件:
DOWN事件被传递给C的onTouchEvent方法,该方法返回true,表示处理这个事件;
因为C正在处理这个事件,那么DOWN事件将不再往上传递给B和A的onTouchEvent();
该事件列的其他事件(Move、Up)也将传递给C的onTouchEvent();
(记住这个图的传递顺序,面试的时候能够画出来,就很详细了)
5.类加载机制
一. 类的加载过程
Person person = new Person();为例进行说明。
1).因为new用到了Person.class,所以会先找到Person.class文件,并加载到内存中;
2).执行该类中的static代码块,如果有的话,给Person.class类进行初始化;
3).在堆内存中开辟空间分配内存地址;
4).在堆内存中建立对象的特有属性,并进行默认初始化;
5).对属性进行显示初始化;
6).对对象进行构造代码块初始化;
7).对对象进行与之对应的构造函数进行初始化;
8).将内存地址付给栈内存中的p变量
二.类的加载器
大家都知道,当我们写好一个Java程序之后,不是管是CS还是BS应用,都是由若干个.class文件组织而成的一个完整的Java应用程序,当程序在运行时,即会调用该程序的一个入口函数来调用系统的相关功能,而这些功能都被封装在不同的class文件当中,所以经常要从这个class文件中要调用另外一个class文件中的方法,如果另外一个文件不存在的,则会引发系统异常。而程序在启动的时候,并不会一次性加载程序所要用的所有class文件,而是根据程序的需要,通过Java的类加载机制(ClassLoader)来动态加载某个class文件到内存当中的,从而只有class文件被载入到了内存之后,才能被其它class所引用。所以ClassLoader就是用来动态加载class文件到内存当中用的。
双亲机制
1、原理介绍
ClassLoader使用的是双亲委托模型来搜索类的,每个ClassLoader实例都有一个父类加载器的引用(不是继承的关系,是一个包含的关系),虚拟机内置的类加载器(Bootstrap ClassLoader)本身没有父类加载器,但可以用作其它ClassLoader实例的的父类加载器。当一个ClassLoader实例需要加载某个类时,它会试图亲自搜索某个类之前,先把这个任务委托给它的父类加载器,这个过程是由上至下依次检查的,首先由最顶层的类加载器Bootstrap ClassLoader试图加载,如果没加载到,则把任务转交给Extension ClassLoader试图加载,如果也没加载到,则转交给App ClassLoader 进行加载,如果它也没有加载得到的话,则返回给委托的发起者,由它到指定的文件系统或网络等URL中加载该类。如果它们都没有加载到这个类时,则抛出ClassNotFoundException异常。否则将这个找到的类生成一个类的定义,并将它加载到内存当中,最后返回这个类在内存中的Class实例对象。
2、为什么要使用双亲委托这种模型呢?
因为这样可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子ClassLoader再加载一次。考虑到安全因素,我们试想一下,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义的类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时就被引导类加载器(Bootstrcp ClassLoader)加载,所以用户自定义的ClassLoader永远也无法加载一个自己写的String,除非你改变JDK中ClassLoader搜索类的默认算法。
3、但是JVM在搜索类的时候,又是如何判定两个class是相同的呢?
JVM在判定两个class是否相同时,不仅要判断两个类名是否相同,而且要判断是否由同一个类加载器实例加载的。只有两者同时满足的情况下,JVM才认为这两个class是相同的。就算两个class是同一份class字节码,如果被两个不同的ClassLoader实例所加载,JVM也会认为它们是两个不同class。比如网络上的一个Java类org.classloader.simple.NetClassLoaderSimple,javac编译之后生成字节码文件NetClassLoaderSimple.class,ClassLoaderA和ClassLoaderB这两个类加载器并读取了NetClassLoaderSimple.class文件,并分别定义出了java.lang.Class实例来表示这个类,对于JVM来说,它们是两个不同的实例对象,但它们确实是同一份字节码文件,如果试图将这个Class实例生成具体的对象进行转换时,就会抛运行时异常java.lang.ClassCaseException,提示这是两个不同的类型。
Android类加载器
对于Android而言,最终的apk文件包含的是dex类型的文件,dex文件是将class文件重新打包,打包的规则又不是简单地压缩,而是完全对class文件内部的各种函数表,变量表进行优化,产生一个新的文件,即dex文件。因此加载这种特殊的Class文件就需要特殊的类加载器DexClassLoader。
6.如何换肤,换肤插件中存在的问题?
1.换肤方案分析
-
res下放多种皮肤的资源文件
-
加载插件apk使用其中的皮肤资源
- 方案一: 优点:容易实现。 缺点:res下放多种皮肤的资源文件,无疑会加大apk文件大小,而且资源文件是写死的,不利于后期拓展,若有其他皮肤需求只能通过版本迭代。
- 方案二: 优点:不会加大apk包,更容易扩展,有新的皮肤只需下载新的插件包即可,无需更新。(相对于方案一) 缺点:相对于方案一实现较困难,若有更多业务处理需要插件,如使用插件中的四大组件及处理它们的生命周期则是比较麻烦的,需用到动态代理。 例如:Android插件化系列第(二)篇—动态加载技术之apk换肤
2.Android换肤技术总结
背景
纵观现在各种Android app,其换肤需求可以归为
- 白天/黑夜主题切换(或者别的名字,通常2套),如同花顺/自选股/天天动听等,UI表现为一个switcher。
- 多种主题切换,通常为会员特权,如QQ/QQ空间。
对于第一种来说,目测应该是直接通过本地theme来做的,即所有图片/颜色的资源都在apk里面打包了。
而对于第二种,则相对复杂一些,由于作为一种线上服务,可能上架新皮肤,且那么多皮肤包放在apk里面实在太占体积了,所以皮肤资源会在选择后再进行下载,也就不能直接使用android的那套theme。
技术方案
内部资源加载方案和动态下载资源下载两种。
动态下载可以称为一种黑科技了,因为往往需要hack系统的一些方法,所以在部分机型和新的API上有时候可能有坑,但相对好处则很多
- 图片/色值等资源由于是后台下发的,可以随时更新
- APK体积减小
- 对应用开发者来说,换肤几乎是透明的,不需要关心有几套皮肤
- 可以作为增值服务卖钱!!
内部资源加载方案
内部资源加载都是通过android本身那套theme来做的,相对业务开发来说工作量更大(需要定义attr和theme),不同方案类似地都是在BaseActivity里面做setTheme,差别主要在解决以下2个问题的策略:
- setTheme后如何实时刷新,而不用重新创建页面(尤其是listview里面的item)。
- 哪些view需要刷新,刷新什么(背景?字体颜色?ImageView的src?)。
自定义view
做自定义view是为了在setTheme后会去立即刷新,更新页面UI对应资源(如TextView替换背景图和文字颜色),在上述项目中,则是通过对rootView进行遍历,对所有实现了ColorUiInterface的view/viewgroup进行setTheme操作来实现即使刷新的。
显然这样太重了,需要把应用内的各种view/viewgroup进行替换。
手动绑定view和要改变的资源类型
这个…我们看看用法吧….
ViewGroupSetter listViewSetter = new ViewGroupSetter(mNewsListView);
// 绑定ListView的Item View中的news_title视图,在换肤时修改它的text_color属性
listViewSetter.childViewTextColor(R.id.news_title, R.attr.text_color);
// 构建Colorful对象来绑定View与属性的对象关系
mColorful = new Colorful.Builder(this)
.backgroundDrawable(R.id.root_view, R.attr.root_view_bg)
// 设置view的背景图片
.backgroundColor(R.id.change_btn, R.attr.btn_bg)
// 设置背景色
.textColor(R.id.textview, R.attr.text_color)
.setter(listViewSetter) // 手动设置setter
.create(); // 设置文本颜色
我就是想换个皮肤,还得在activity里自己去设置要改变哪个view的什么属性,对应哪个attribute?是不是成本太高了?而且activity的逻辑也很容易被弄得乱七八糟。
动态资源加载方案
resource替换
覆盖application的getResource方法,实现自己的resource,优先加载本地皮肤包文件夹下的资源包,对于性能问题,可以通过attribute或者资源名称规范(如需要换肤则用skin_开头)来优化,从而不对不换肤的资源进行额外检查开销。
不过由于Android5.1源码里,drawable初始化的时候调用的是loadDrawable,而不是resource.getDrawable,而loadDrawable是私有的方法,无法覆盖,所以虽然很方便,却无法继续使用(不用关心任何皮肤相关的事情,android:color指定颜色就行了,神奇滴会自动换肤)。
自定义LayoutInflator.Factory
开源项目可参照Android-Skin-Loader。
即setFactory使用自定义的LayoutInflator.Factory,可以重点关注该项目中的SkinInflaterFactory和SkinManager(实现了自己的getColor、getDrawable、getBitmap、getColorStateList等等方法)。
需要自定义一个tag比如app:customStyle,重写所有的style,转成set方法,这样带来的牺牲就是增加了换肤的成本,要写很多style,自己去set,并不完全透明了。
Hack Resources internally
黑科技方法,直接对Resources进行hack,Resources.Java:
// Information about preloaded resources. Note that they are not
// protected by a lock, because while preloading in zygote we are all
// single-threaded, and after that these are immutable.
private static final LongSparseArray<Drawable.ConstantState>[] sPreloadedDrawables;
private static final LongSparseArray<Drawable.ConstantState> sPreloadedColorDrawables
= new LongSparseArray<Drawable.ConstantState>();
private static final LongSparseArray<ColorStateList> sPreloadedColorStateLists
= new LongSparseArray<ColorStateList>();
直接对Resources里面的这三个LongSparseArray进行替换,由于apk运行时的资源都是从这三个数组里面加载的,所以只要采用interceptor模式:
public class DrawablePreloadInterceptor extends LongSparseArray
自己实现一个LongSparseArray,并通过反射set回去,就能实现换肤,具体getDrawable等方法里是怎么取preload数组的,可以自己看Resources的源码。
等等,就这么简单?,NONO,少年你太天真了,怎么去加载xml,9patch的padding怎么更新,怎么打包/加载自定义的皮肤包,drawable的状态怎么刷新,等等。这些都是你需要考虑的,在存在插件的app中,还需要考虑是否会互相覆盖resource id的问题,进而需要修改apt,把resource id按位放在2个range。
手Q和独立版QQ空间使用的是这种方案,效果挺好。
总结
尽管动态加载方案比较黑科技,可能因为系统API的更改而出问题,但相对来说
好处有
- 灵活性高,后台可以随时更新皮肤包
- 相对透明,开发者几乎不用关心有几套皮肤,不用去定义各种theme和attr,甚至连皮肤包的打包都可以交给设计或者专门的同学
- apk体积节省
存在的问题
没有完善的开源项目,如果我们采用动态加载的第二种方案,需要的项目功能包括:
- 自定义皮肤包结构
- 换肤引擎,加载皮肤包资源并load,实时刷新。
- 皮肤包打包工具
- 对各种rom的兼容
如果有这么一个项目的话,就一劳永逸了,有兴趣的同学可以联系一下,大家一起搞一搞。
内部加载方案大同小异,主要解决的都是即时刷新的问题,然而从目前的一些开源项目来看,仍然没有特别简便的方案。让我选的话,我宁愿让界面重新创建,比如重启activity,或者remove所有view再添加回来(或者你可能想遍历rootview,然后一个个检查是否需要换肤然后set…)。
7.hotfix是否用过,原理是否了解?
8.说说项目中用到了哪些设计模式,说了一下策略模式和观察者模式?
1.单例模式(application、eventBus) 2.builder创建模式(AlertDialog、Glide、OkHttp) 3.观察者模式(ListView、RxJava,监听事件) 4.装饰模式(context) 5.外观模式(contextImpl) 6.模板方法模式(Activity和Fragment生命周期、AsyncTask、BaseActivity) 7.策略模式(Volley、属性动画、插值器 Interpolator) 8.组合模式(View、ViewGroup) 9.代理模式(binder) 10.迭代器模式(Iterator) 11.命令模式(Runnable) 12.原型模式(Intent) 13.责任链模式(try-catch语句、有序广播、事件分发机制) 14.桥接模式bridge(listview和BaseAdapter) 15.适配器模式(BaseAdapter类)
9.会JS么?有Hybid开发经验么?
为什么引入Hybrid开发 混合开发是 Native 和 Web 技术一起用,开发者以 Native 代码为主体,在合适的地方部分使用 Web 技术。比如在 Android 中的 Activity 内放置一个 Webview(一个浏览器引擎,只拥有渲染 HTML,CSS 和执行 JavaScript 的核心功能)。这样,部分用户界面就可以在 WebView 中使用 Web 技术实现。
促使我们在移动开发中使用 Web 技术主要动力在于,相比于 Native 技术,Web 技术具有诸多优势:
-
高效率的界面开发:HTML,CSS,JavaScript 的组合被证明在用户界面开发方面具有很高的效率。
-
跨平台:统一的浏览器内核标准,使得 Web 技术具有跨平台特性。iOS 和 Android 可以使用一套代码。
-
热更新:可越过发布渠道自主更新应用。
这些优势都和开发效率有关。Web 技术具有这些优势的原因是,Web 技术是一个开放标准。基于开放的标准已经发展出来庞大生态,而且这个生态从 PC 时代发展至今已积累多年,开发者可以利用生态中产出的各种成果,从而省去很多重复工作。
在大型移动应用的开发中,项目代码庞杂,通常还需要 iOS,Android,移动 Web 和 桌面 Web 全平台支持。相对于同时开发几个版本,使用混合开发显然可以在代码重用、开发成本和效率方面有很大的优势,在权衡性能体验的前提下,使用混合开发是非常现实的选择。
实现方式 一般来讲,也是我目前知道的两种主流的方式就是
- js调用Native中的代码
- Schema:WebView拦截页面跳转
第2种方式实现起来很简单,但是一个致命的问题就是这种交互方式是单向的,Html 5无法实现回调。像云音乐App中这种点击跳转到具体页面的功能,Schema的方式确实可以简单实现,而且也非常适合。如果需求变得复杂,假如Html 5需要获取Native App中的用户信息,那么最好使用js调用的方式。
JS安全漏洞 Android API level 16以及之前的版本存在远程代码执行安全漏洞,该漏洞源于程序没有正确限制使用WebView.addJavascriptInterface方法,远程攻击者可通过使用Java Reflection API利用该漏洞执行任意Java对象的方法,简单的说就是通过addJavascriptInterface给WebView加入一个JavaScript桥接接口,JavaScript通过调用这个接口可以直接操作本地的JAVA接口。该漏洞最早公布于CVE-2012-6636【1】,其描述了WebView中addJavascriptInterface API导致的远程代码执行安全漏洞。
js调用的方式
WebView.addJavascriptInterface(Object o, String interface)方法注册可供js调用的Java对象
addJavascriptInterface(mJsBridge, mWindowClientName);
在mJsBridge对象中封装一些供js调用的Java方法,例如有loading框显示与隐藏,页面关闭的统一动画,dialog的显示,toast的显示,调用native系统的打开相册,打开通讯录,打电话,发短信等
Schema的方式 通过shouldOverrideUrlLoading方法拦截url,如果host是内定的协议就打开对应协议的activity,如果是正常的url的HTTP或者HTTPS就正常loadUrl,否则就是默认是系统协议处理,打开系统页面,例如调起拨打电话。
public final boolean filter(Context context, String url) {
mContext = context;
if (null == mContext || TextUtils.isEmpty(url)) {
return true;
}
//普通url
if (url.startsWith("http://") || url.startsWith("https://")) {
return dealWithHttp(url);
}
//更美协议
if (url.startsWith(mProtocolName)) {
return dealWithProtocol(url);
}
//系统协议
return dealWithSystemProtocol(url); }
/**
* 普通url处理 * * @param url
* @return
*/ protected boolean dealWithHttp(String url) {
if (null != mOnLoadUrlListener && mWhiteList.inWhiteList(url)) {
mOnLoadUrlListener.onLoadUrl(url);
}
return true; }
/**
* 协议处理 * * @param url
* @return
*/ protected boolean dealWithProtocol(String url) {
try {
if (mContext instanceof GMActivity) {
((GMActivity) mContext).startActivityForResult(new Intent(Intent.ACTION_VIEW, Uri.parse(url)), 1024);
} else if (mContext instanceof Activity) {
((Activity) mContext).startActivityForResult(new Intent(Intent.ACTION_VIEW, Uri.parse(url)), 1024);
}
} catch (Exception e) {
e.printStackTrace();
}
return true; }
/**
* 系统协议处理,eg:tel(拨打电话) * @param url
* @return
*/ protected boolean dealWithSystemProtocol(String url){
try {
if (mContext instanceof GMActivity) {
((GMActivity) mContext).startActivityForResult(new Intent(Intent.ACTION_VIEW, Uri.parse(url)), 1024);
} else if (mContext instanceof Activity) {
((Activity) mContext).startActivityForResult(new Intent(Intent.ACTION_VIEW, Uri.parse(url)), 1024);
}
} catch (Exception e) {
e.printStackTrace();
}
return true; }
10.说一下快排的思想?手写代码
基本思想:选择某个元素作为基准元素,通常选择第一个元素或者最后一个元素,通过一趟扫描,将待排序列分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后再用同样的方法递归地排序划分的两部分,最终整个数组将变成有序的。


public static void quickSort(int[] array) {
_quickSort(array, 0, array.length - 1);
System.out.println(Arrays.toString(array) + " quickSort");
}
private static int getMiddle(int[] list, int low, int high) {
int tmp = list[low]; //数组的第一个作为中轴
while (low < high) {
while (low < high && list[high] >= tmp) {
high--;
}
list[low] = list[high]; //比中轴小的记录移到低端
while (low < high && list[low] <= tmp) {
low++;
}
list[high] = list[low]; //比中轴大的记录移到高端
}
list[low] = tmp; //中轴记录到尾
return low; //返回中轴的位置
}
private static void _quickSort(int[] list, int low, int high) {
if (low < high) {
int middle = getMiddle(list, low, high); //将list数组进行一分为二
_quickSort(list, low, middle - 1); //对低字表进行递归排序
_quickSort(list, middle + 1, high); //对高字表进行递归排序
}
}
(1) 枢轴的选取方式的优化:
枢轴的选取方式有:(1) 固定位置选取;(2) 随机位置选取; (3) 三值取中法 等
固定位置选取:选取当前序列的第一个元素或者最后一个元素作为枢轴,上面的算法的枢轴选取方式即为固定位置选取。该方法不是一个好的选取方案,因为当整个序列有序时,每次分割(partition)操作只会将待排序序列减1,此时为最坏情况,算法复杂度沦为O(n^2)。然而,在待排序的序列中局部有序是相当常见的,所以固定位置选取枢轴不是一种好的选择。
随机位置选取:随机选取当前待排序序列的任意记录作为枢轴。由于采取随机,所以时间性能要强于固定位置选取。
三值取中法: 待排序序列的前(第一个位置)、中(中间位置)、后(最后一个位置)三个记录中的中间值(按大小排序)作为枢轴
三值取中本质上就是随机位置选取,但是由于随机位置选取过程中需要用到随机种子来产生随机数,而三值取中不需要,所以三值取中要优于随机位置选取。
所以优化枢轴的选取方式时,我们选择三值取中的方式。
(2) 优化小数组时的排序方案:
当局部排序数组长度较小时,采用插入排序,而非快速排序,因为长度分割到够小后,继续分割的效率要低于直接插入排序。
(3) 略去不必要的交换
略去不必要的交换,将交换操作改为替换操作。
因为交换操作需要进行3次赋值操作,而替换操作只需要进行1次赋值操作。
Java实现
// 优化的快速排序
class OptimizedQuickSorter extends QuickSorter {
/**
* 插入排序最大数组长度值
*/
private static final int MAX_LENGTH_INSERT_SORT = 7;
/**
* 对数组arr[low...high]的子序列作快速排序,使之有序
*/
@Override
protected void quickSort(int[] arr, int low, int high) {
int pivotLoc; // 记录枢轴(pivot)所在位置
if ((high - low + 1) > MAX_LENGTH_INSERT_SORT) {
// 待排序数组长度大于临界值,则进行快速排序
pivotLoc = partition(arr, low, high); // 将arr[low...high]一分为二,并返回枢轴位置
quickSort(arr, low, pivotLoc - 1);// 递归遍历arr[low...pivotLoc-1]
quickSort(arr, pivotLoc + 1, high); // 递归遍历arr[pivotLoc+1...high]
} else {
// 2\. 优化小数组时的排序方案,将快速排序改为插入排序
insertSort(arr, low, high); // 对arr[low...high]子序列进行插入排序
}
}
/**
* 在arr[low...high]中利用三值取中选取枢轴(pivot),将arr[low...high]分成两部分,
* 前半部分的子序列的记录均小于pivot,后半部分的记录均大于pivot;最后返回pivot的位置
*/
@Override
protected int partition(int[] arr, int low, int high) {
int pivot;
pivot = medianOfThree(arr, low, high); // 1\. 优化排序基准,使用三值取中获取中值
while (low < high) { // 从数组的两端向中间扫描 // A
while (low < high && arr[high] >= pivot) { // B
high--;
}
// swap(arr, low, high); // 将比枢轴pivot小的元素交换到低位
arr[low] = arr[high]; // 3\. 优化不必要的交换,使用替换而不是交换 // C
while (low < high && arr[low] <= pivot) { // D
low++;
}
// swap(arr, low, high); // 将比枢轴pivot大的元素交换到高位
arr[high] = arr[low]; // 3\. 优化不必要的交换,使用替换而不是交换 // E
}
arr[low] = pivot; // F
return low; // 返回一趟下来后枢轴pivot所在的位置
}
/**
* 通过三值取中(从arr[low...high]子序列中)获取枢轴pivot的值,让arr[low]变成中值;并返回计算的枢轴(pivot)
*/
private int medianOfThree(int[] arr, int low, int high) {
int mid = low + ((high - low) >> 1); // mid = low + (high-low)/2, 中间元素下标
// 使用三值取中得到枢轴
if (arr[low] > arr[high]) { // 目的:让arr[low] <= arr[high]
swap(arr, low, high);
}
if (arr[mid] > arr[high]) { // 目的:让arr[mid] <= arr[high]
swap(arr, mid, high);
}
if (arr[mid] > arr[low]) { // 目的: 让arr[low] >= arr[mid]
swap(arr, low, mid);
}
// 经过上述变化,最终 arr[mid]<=arr[low]<=arr[high],则arr[low]为中间值
return arr[low];
}
/**
* 对子序列arr[low...high]进行插入排序
*/
private void insertSort(int[] arr, int low, int high) {
int i, j;
int tmp;
for (i = low + 1; i <= high; i++) { // 从下标low+1开始遍历,因为下标为low的已经排好序
if (arr[i] < arr[i - 1]) {
// 如果当前下标对应的记录小于前一位记录,则需要插入,否则不需要插入,直接将记录数增加1
tmp = arr[i]; // 记录下标i对应的元素
for (j = i - 1; j >= low && arr[j] > tmp; j--) {
arr[j + 1] = arr[j]; // 记录后移
}
arr[j + 1] = tmp; // 插入正确位置
}
}
}
}
复杂度
时间复杂度:
时间复杂度为O(nlogn),在对快速排序进行各种细节性的优化后,快速排序的性能大大提高,在一般条件下超越了其它排序方法,故得此名。
空间复杂度:
就空间复杂度来说,主要是递归造成的栈空间的使用,最好情况,递归的深度为log2n,其空间复杂度也就为O(logn),最坏情况,需要进行n‐1递归调用,其空间复杂度为O(n),平均情况,空间复杂度也为O(logn)。
11.堆有哪些数据结构?
对于这轮面试明显感觉到压力,知识的纵向了解也比较深,应该是个leader.
第三轮
1.介绍一下在项目中的角色?
2.遇到困难是怎么解决的?
3.如何与人相处,与别人意见相左的时候是怎么解决的,并举生活中的一个例子.
4.有没有压力特别大的时候?
这个应该是项目经理了,问的问题偏向于生活性格方面.
以上面试中问到的题目基本上都可以在上面找到答案,所以做准备是很重要的,但技术是一点点积累的,就算你全会背了,面试过了,真正等到工作的时候还是会捉襟见肘的,所以踏实点吧骚年.